Serviço Sinapses - Inteligência Artificial
Histórico
Em meados de 2017 o TJRO instituiu uma equipe formada por 4(quatro) analistas, com intuito de prospectar o uso de IA para celeridade do processo judicial.
Várias empresas foram contactadas, porém não havia nada no mercado com maturidade suficiente para atender a demanda exigida.O intuito naquele momento, era atender à uma solicitação do Desembargador Walter Waltenberg, que almejava a automatização do processo de concessão de medicamentos, minimizando o esforço realizado por seus assessores em pesquisas e triagens.
Diante da demanda, a então Secretária de TIC, Ângela Carmen, instituiu um setor de inovação, coordenado pela Diretora do DeGov Alessandra Lima.
Uma frente de trabalho para contratação de empresas foi criada, realizando um Estudo Técnico Preliminar (ETP), que culminaria em 4 (quatro) processos distintos de aquisição. Parte da equipe realizou viagens de sondagem, para conhecer sistemas similares já existentes em outros órgãos e empresas privadas.
Na esfera pública, os sistemas Aptus(MPF) e Sapiens(AGU) foram as soluções mais robustas encontradas, porém atendiam apenas em parte as necessidades e eram de difícil customização ao modelo de negócio do TJRO.
Em paralelo ao processo de contratação, a equipe foi encubida de realizar treinamentos em DataScience e Inteligência Artificial com a finalidade de desenvolver internamente a ferramenta preterida.
A escolha foram treinamentos da DataScience Academy, os quais serviram de norte para os integrantes da equipe, iniciando o treinamento em Outubro de 2017.
Em janeiro de 2018, os primeiros resultados já puderam ser observados no desenvolvimento realizado pela equipe do TJRO, que apresentou uma POC de um modelo de para classificação de despachos. A demonstração agradou aos gestores e ao atual Presidente Desembargador Walter Waltenberg, que disponibilizaram servidores da área negocial com intuito de treinar novos modelos de inteligência artificial.
Até então, não havia ainda uma plataforma nos moldes atuais, e dada a necessidade de gerar novos modelos com maior celeridade, possibilitando um interfaciamento com novos sistemas e a curadoria, ficou clara a necessidade de uma orquestração que foi totalmente agnóstica do ponto de vista de software, nascia ali o arcabouço do que viria a ser chamado de SINAPSES.
O nome SINAPSES foi escolhido por votação, entre os servidores do DeGov-TJRO.
Com uma inteface mais madura, possibilitando que novos modelos fossem treinados, as equipe de negócio iniciaram o treinamento de novos modelos, possibilitando o avanço nos trabalhos de pesquisa que vinham sendo desenvolvidos.
O projeto passou a ter noteriedade no cenário nacional, tem sido exposto em dois eventos que acabaram sendo marcos em sua trajetória, a CampusParty-RO e o Fórum de Inteligência Artificial do TSE, ocorridos entre junho e agosto de 2018.
O CNJ tomou conhecimento do projeto, e em setembro de 2018, realizou a primeira visita - coordenada pelo Juiz Auxiliar do CNJ Braúlio Gabriel Gusmão - ao TJ-RO para conhecer a plataforma. A visão da equipe em relação ao sistema ia de encontro com os anseios do CNJ, em prover um ambiente ancorado em microserviços, que não tolhesse a capacidade de inovar dos tribunais.
Deste encontro, saiu o compromisso de nacionalizar o SINAPSES para atender ao judiciário nacional, o que foi feito em 16 de outubro de 2018, através do Termo de Cooperação 42/2018, assinados pelo Presidente do CNJ, ministro Dias Toffoli e o presidente do TJ-RO, desembargador Walter Waltenberg.

Inova PJe
Um espaço para pensar, pesquisar e produzir inovação para o processo judicial eletrônico. Com intuito de ser uma comunidade no judiciário, com foco na inovação do PJe, foi instituido o Laboratório de Inovação do Processo Judicial Eletrônico (InovaPJe)
Portaria 25/2019 CNJ - Institui o Laboratório de Inovação http://www.trtsp.jus.br/geral/tribunal2/Trib_Sup/STF/CNJ/Port_25_19.html.
Edital 02/2019 CNJ - Abre processo de seleção para projetos em IA http://www.trtsp.jus.br/geral/tribunal2/Trib_Sup/STF/CNJ/Edital_02_19.html.
Vantagens
-
Datasets da justiça nacional, de modo a possibilitar o estudo e treinamento de modelos de inteligência artificial sobre bases reais;
-
O Centro de Inteligência Artificial operará como um acelerador de resultados, ao tornar disponível ferramentas, dados, consultoria técnica e intelectual, bem como um ambiente de colaboração entre os pesquisadores. O objetivo é escalar as iniciativas de todo país para sublimação tecnológica do PJe com uso da inteligência artificial.
-
Ambiente de comunidade, de modo a facilitar a troca de experiências e o trabalho entre pesquisadores;
-
Compartilhamento dos modelos de IA criados
-
Participação preferencial nas novas iniciativas prospectadas a partir das atividades desenvolvidas no Centro de Inteligência Artificial, tais como seminários, fóruns, palestras e treinamentos;
-
O fornecimento dos subsídios necessários ao sucesso dos projetos.
O que é
O sistema SINAPSES é uma plataforma para desenvolvimento e disponibilização em larga escala de modelos de inteligência artificial, também comumente conhecido como “Fábrica de Modelos de IA”. Esta terminologia se deve ao fato de a plataforma possibilitar que o processo de entrega dos modelos seja acelerado em uma escala não permitida quando estes são desenvolvidos da forma tradicional, onde o cientista de dados e os desenvolvedores trabalham em conjunto para acoplar a inteligência ao sistema nativamente, muitas vezes incorporando ao código (fortemente acoplado) do sistema a inteligência.
No SINAPSES, esta atividade acontece de uma forma diferente, o sistema cliente (que irá consumir a inteligência) opera de forma totalmente independente do processo de construção dos modelos de inteligência artificial, consumindo micro serviços, também conhecidos como API’s, possibilitando assim total liberdade para as equipes de DataScience e também de Desenvolvedores, trabalhando em uma abordagem fracamente acoplada.
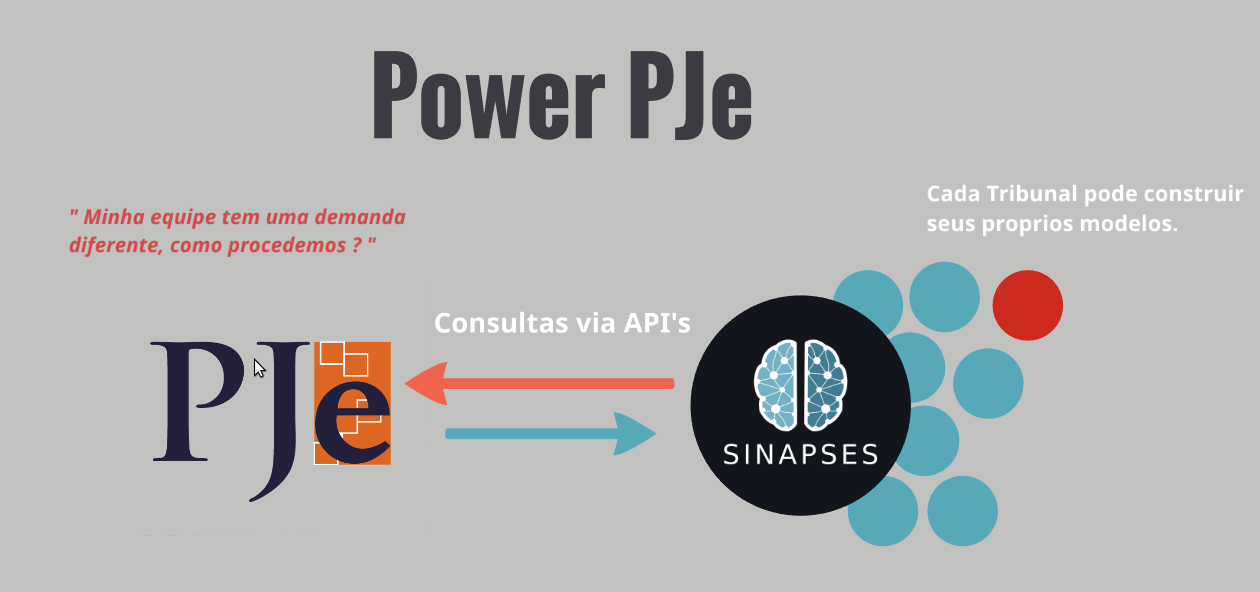
Prover um mercado de modelos para serem utilizado no PJe, possibilitando que estes modelos possam ser utilizados pelas diversas versões, e que cada tribunal possa construir seus proprios modelos, compartilha-los e consumir modelos de outros tribunais.
Funcionalidades
Treinamento supervisionado para modelos de machine learning
A plataforma oferece uma interface que possibilita o treinamento supervisionamento de modelos de classificação ou extração de texto. De forma simples, a curadoria pode ser realizadas pelas equipes de negócio, possibilitando a criação de novos modelos que necessitem de treinamento supervisionado.
Classificação de Documentos
Extração de texto
Versionamento de Modelos
Uma das grandes vantagens no SINAPSES está na seu suporte ao versionamento de modelos de IA. É possível manter várias versões do mesmo modelo ativas, e criar novas versões a partir do algoritmo de versões anteriores ou novos algoritmos, acompanhando a evolução do modelo quanto a sua acurácia, situação, data de início e fim de treinamento, situação e status, gestão de recursos, algoritmo, dependências do container, gestão de réplicas e monitoramento de pods hospedados na infra-estrutura.
Tela de informações de todas as versões disponíveis por modelo
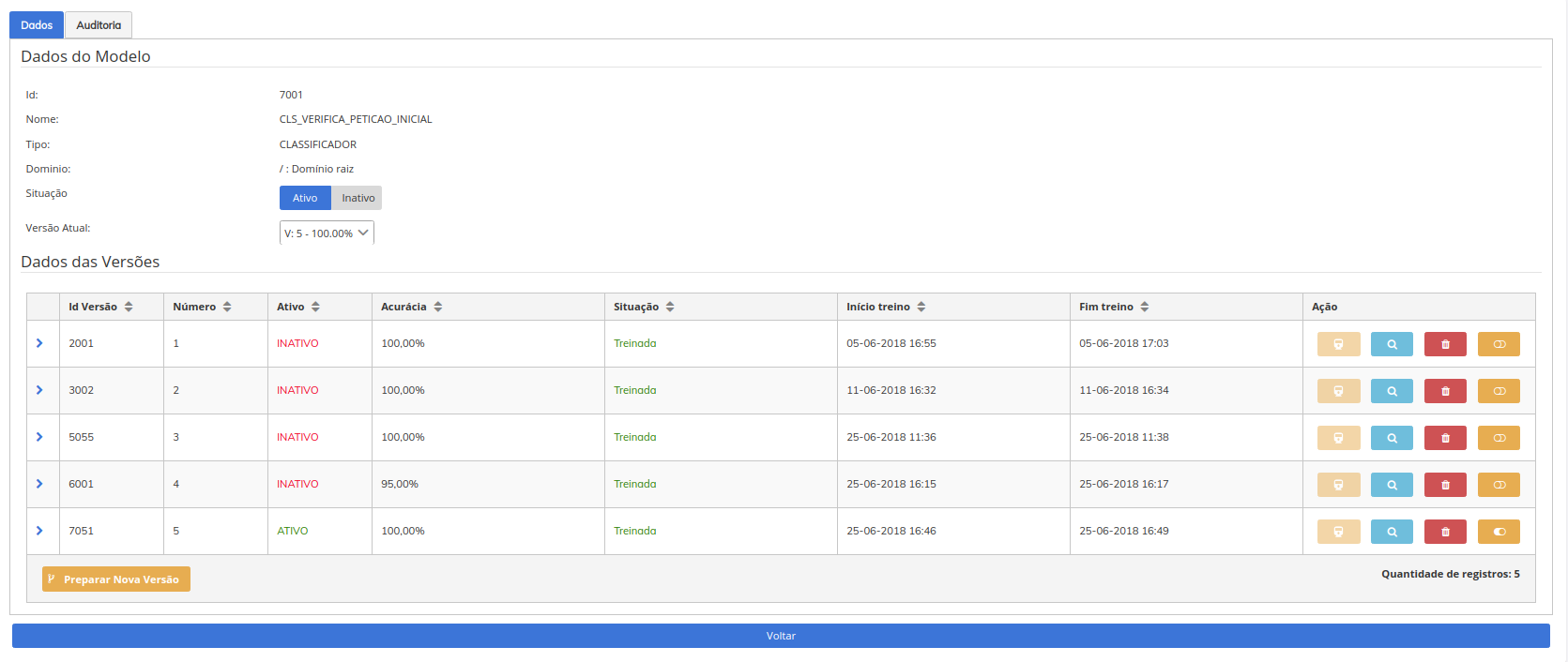
Tela de informações do modelo
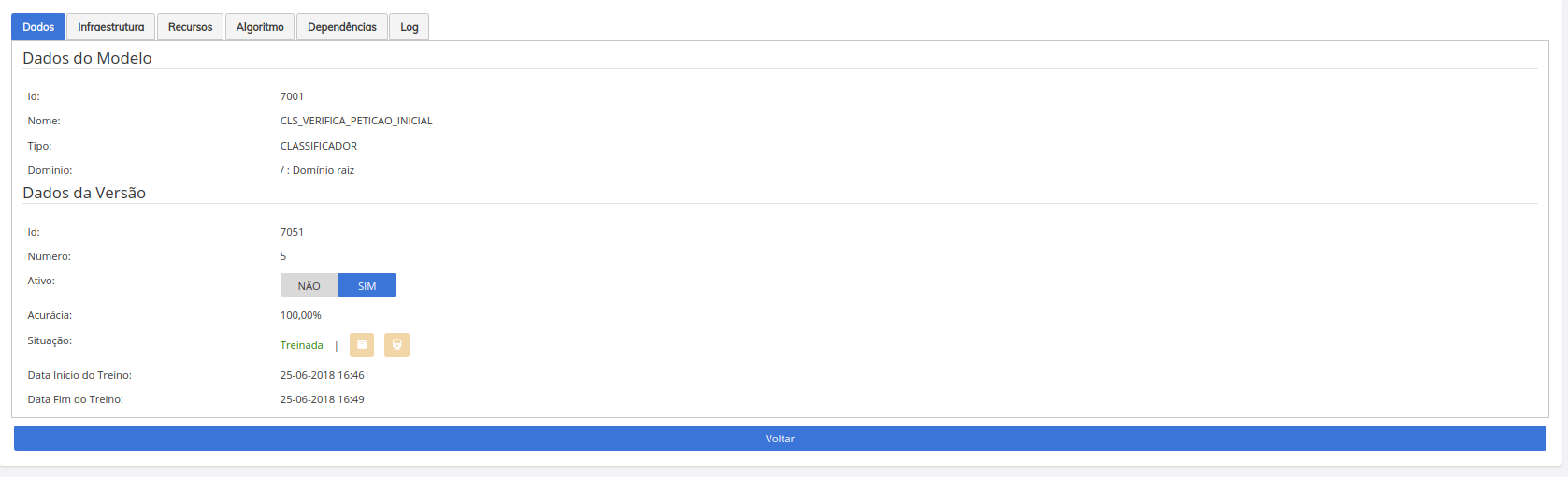
Tela de gestão de réplicas
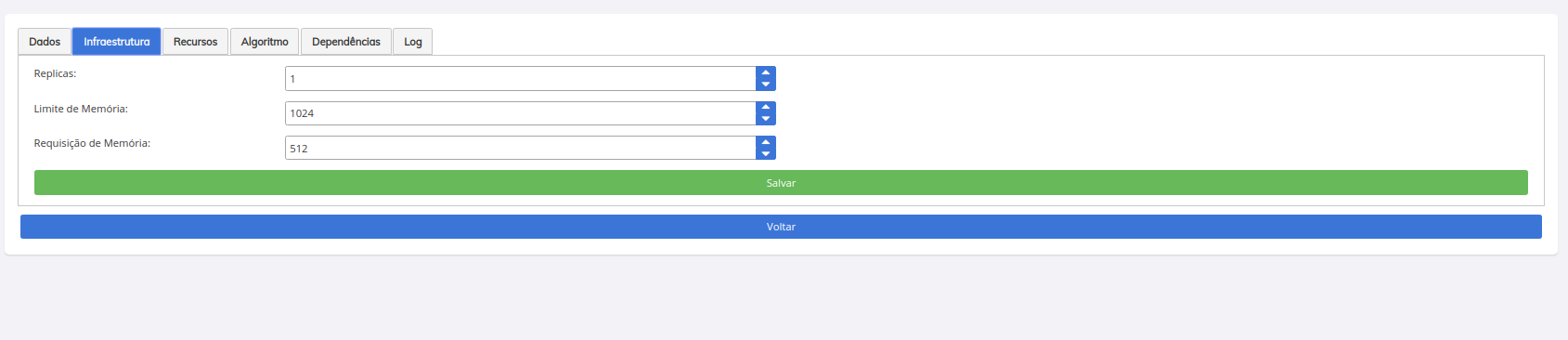
Tela gestão de recursos
Tela de algoritmo
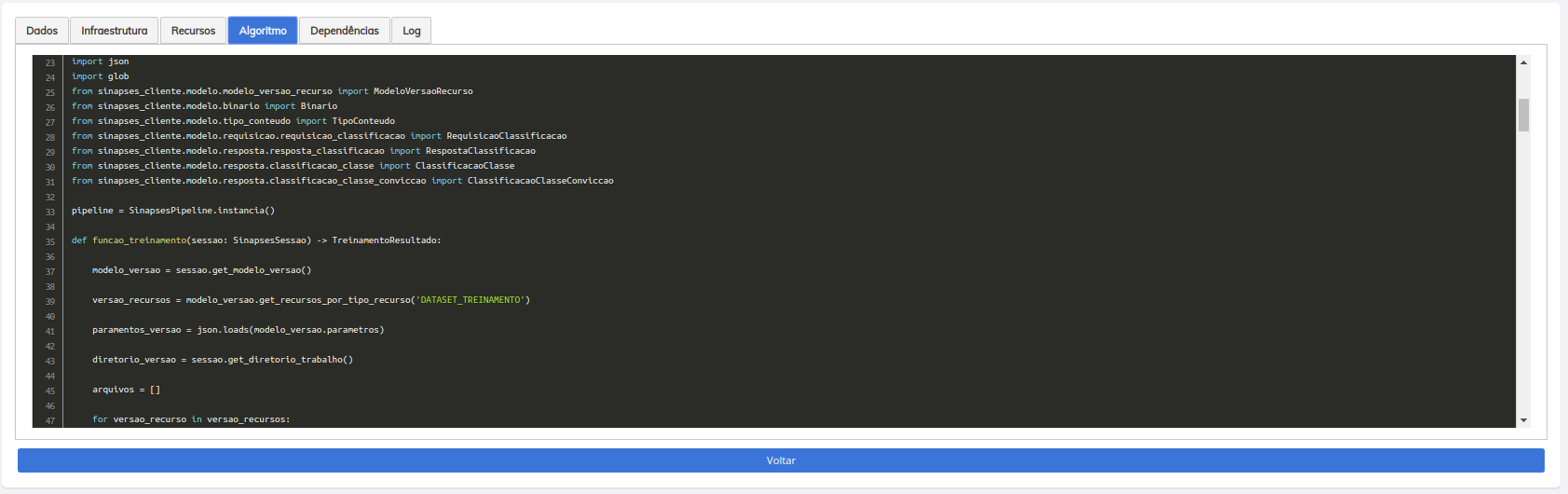
Tela de dependências
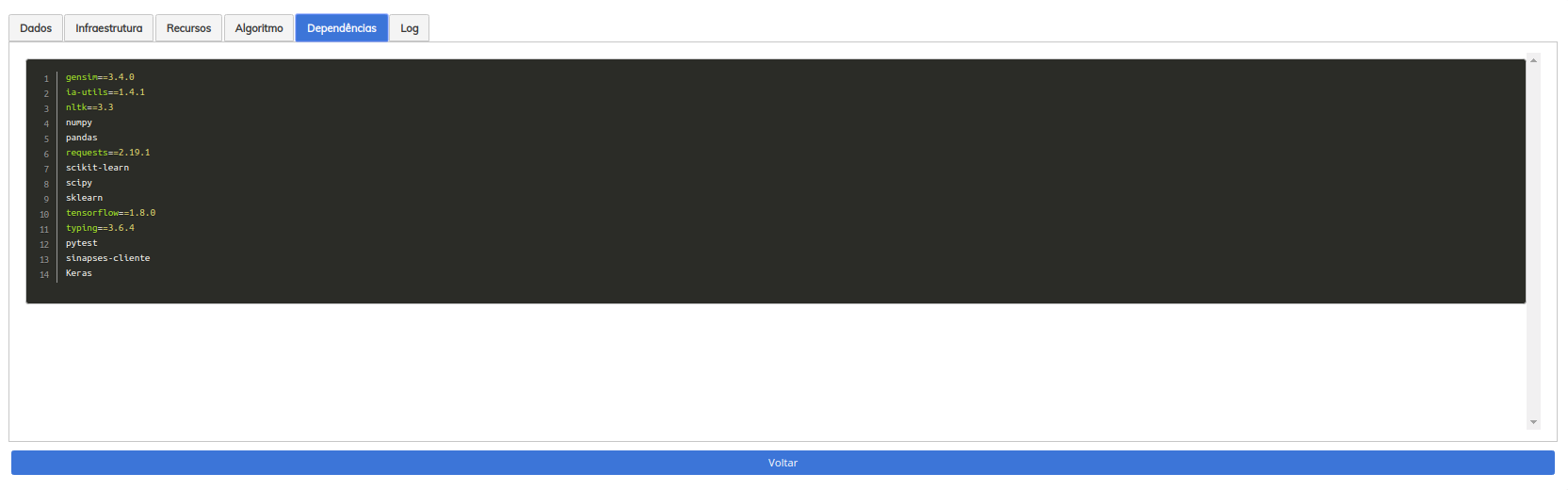
Tela de gestão de pods (pod saudável)
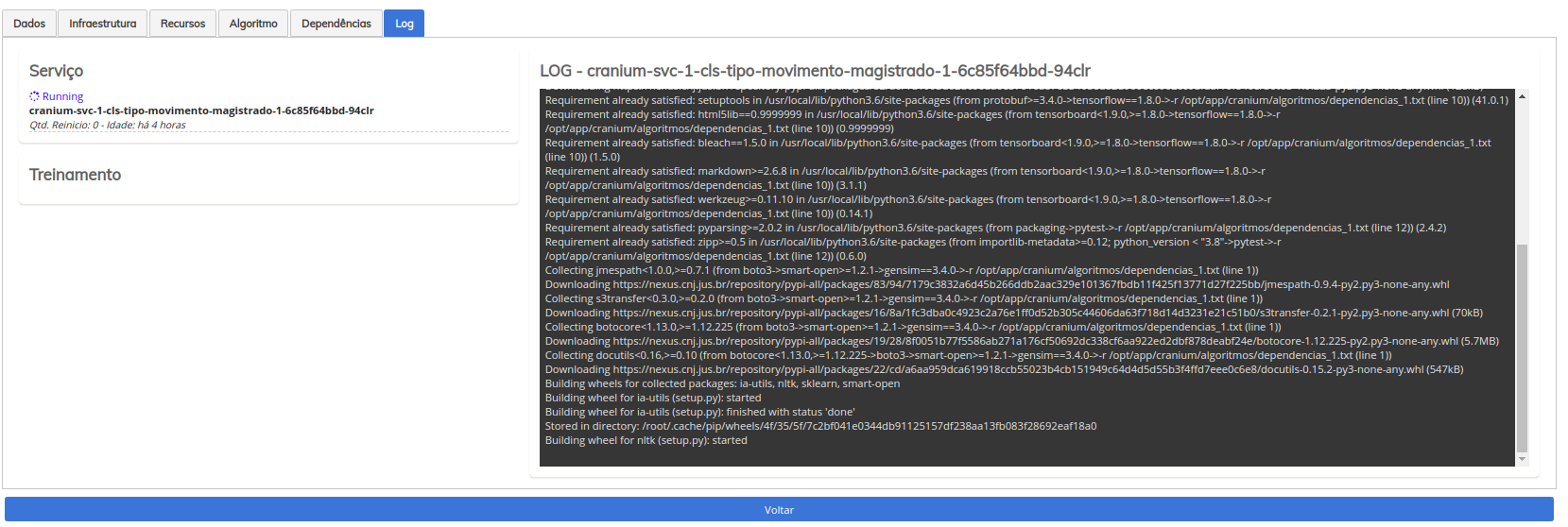
Tela de gestão de pods (pod com erro)

Auditabilidade dos modelos
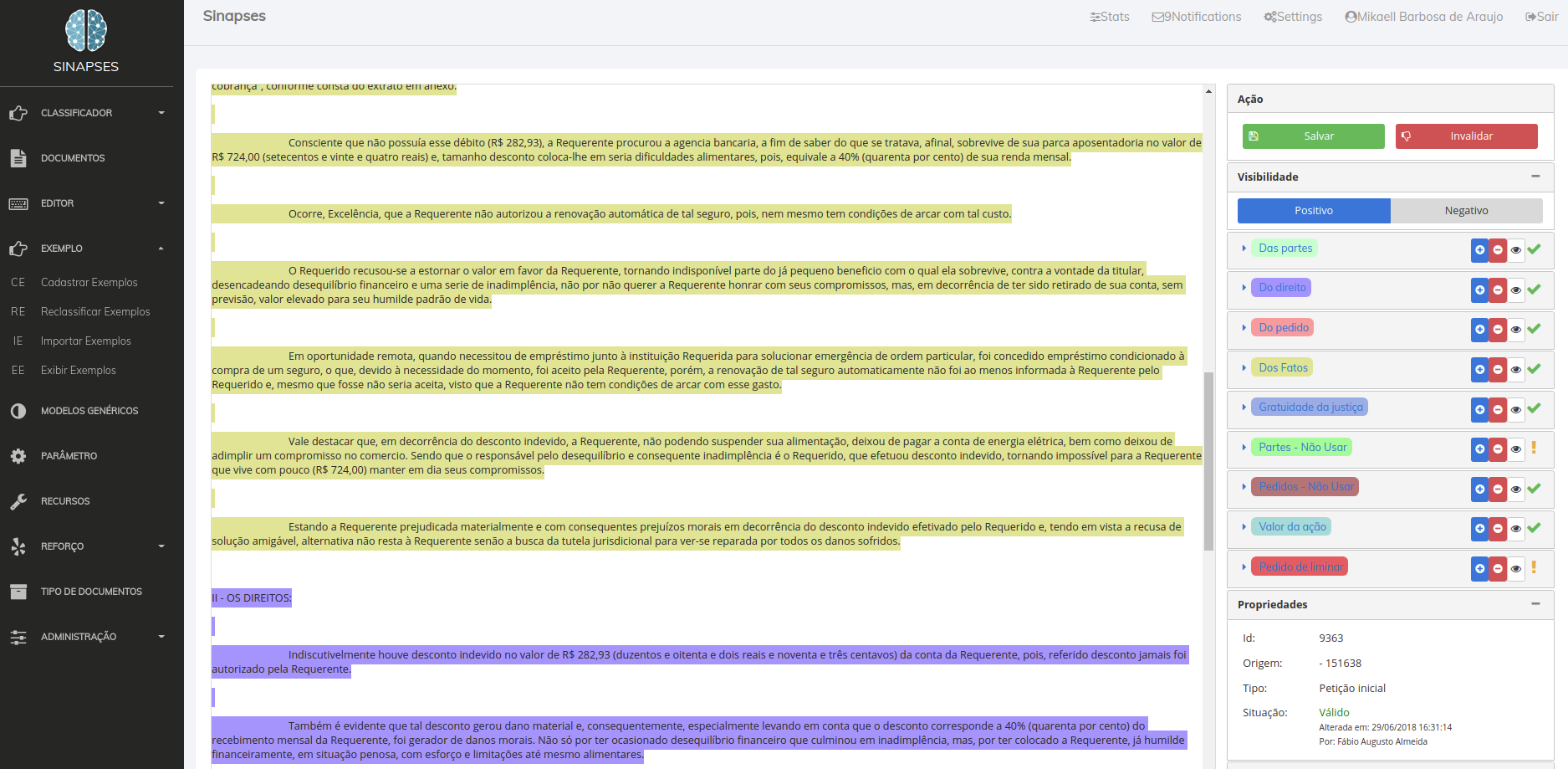
É possível gerenciar o comportamento dos modelos em produção, provendo um ciclo de auditabilidade do mesmo. Isso é possível pois cada modelo pode ter suas predições auditadas a cada requisição, gerando um relatório que contém a convicção, classe (rótulo, label) predita, a data, o nome do classificador e o documento que foi enviado para predição. A partir destas informações, e do processo de desenvolvimento que cada modelo possui dentro da plataforma ( extração, treinamento, algoritmo, dependências), podemos garantir uma oferta mínima de revisão do processo de sugestões realizadas pela IA. Aliando esta funcionalidade, a necessidade de validação ética e jurídica dos modelos que são disponibilizado em produção, estaremos ofertando uma governança da atuação da IA dentro do processo judicial.
Tela de Predições
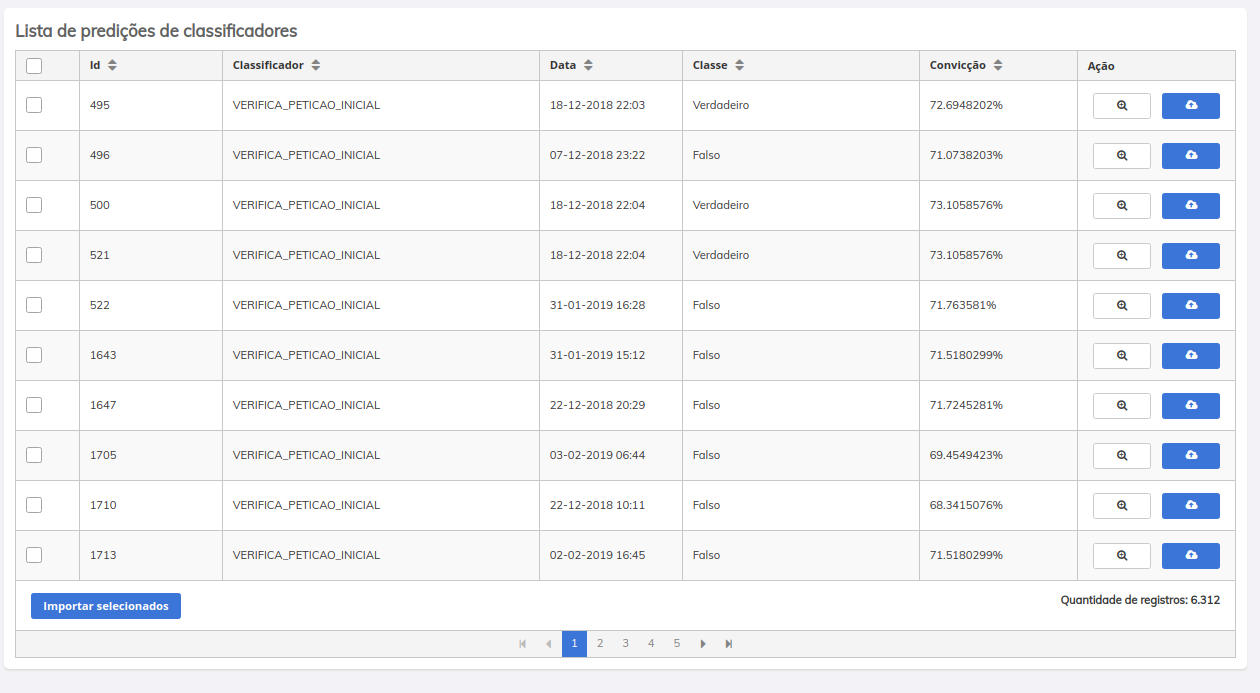
Documento enviado para predição
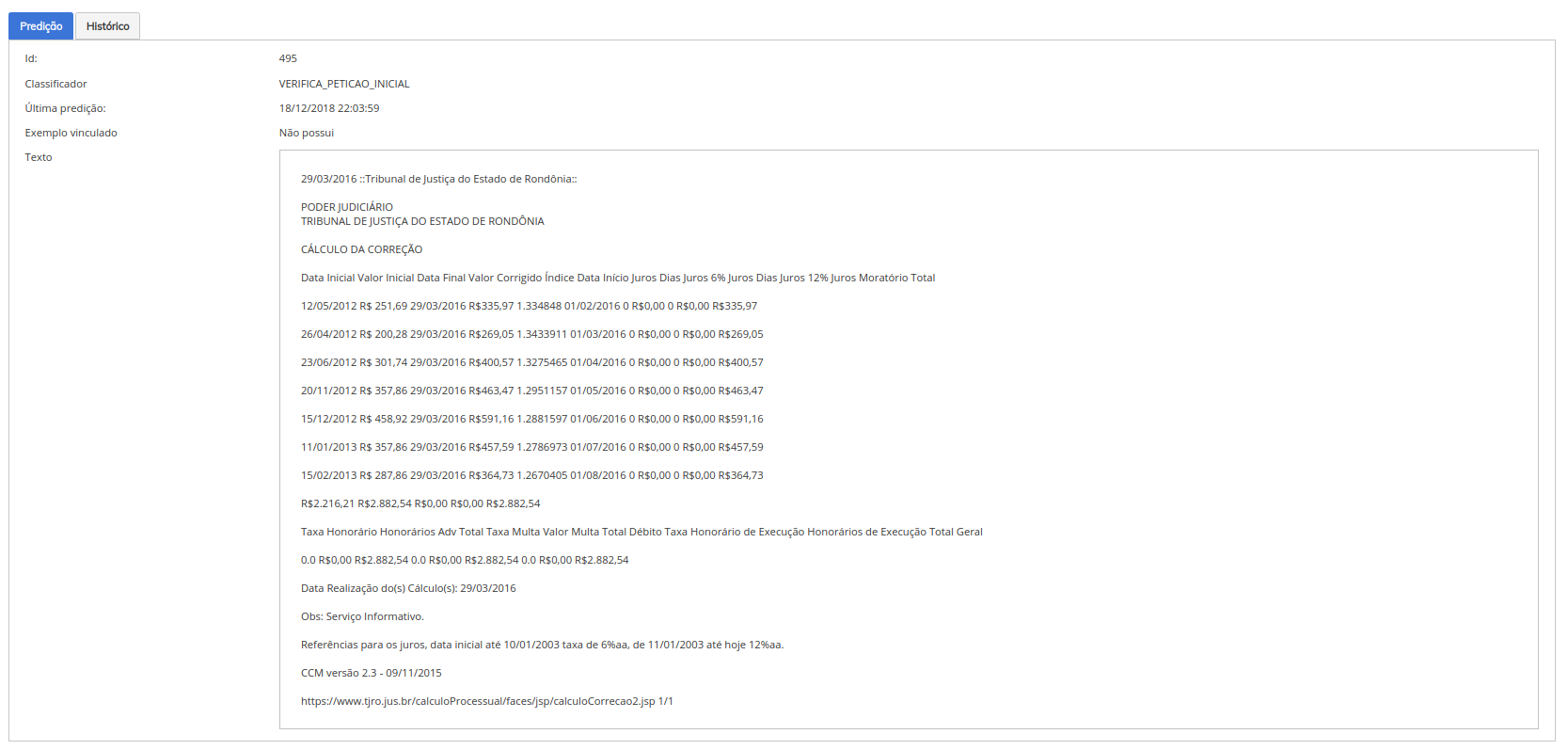
Histórico de predições realizadas para um documento

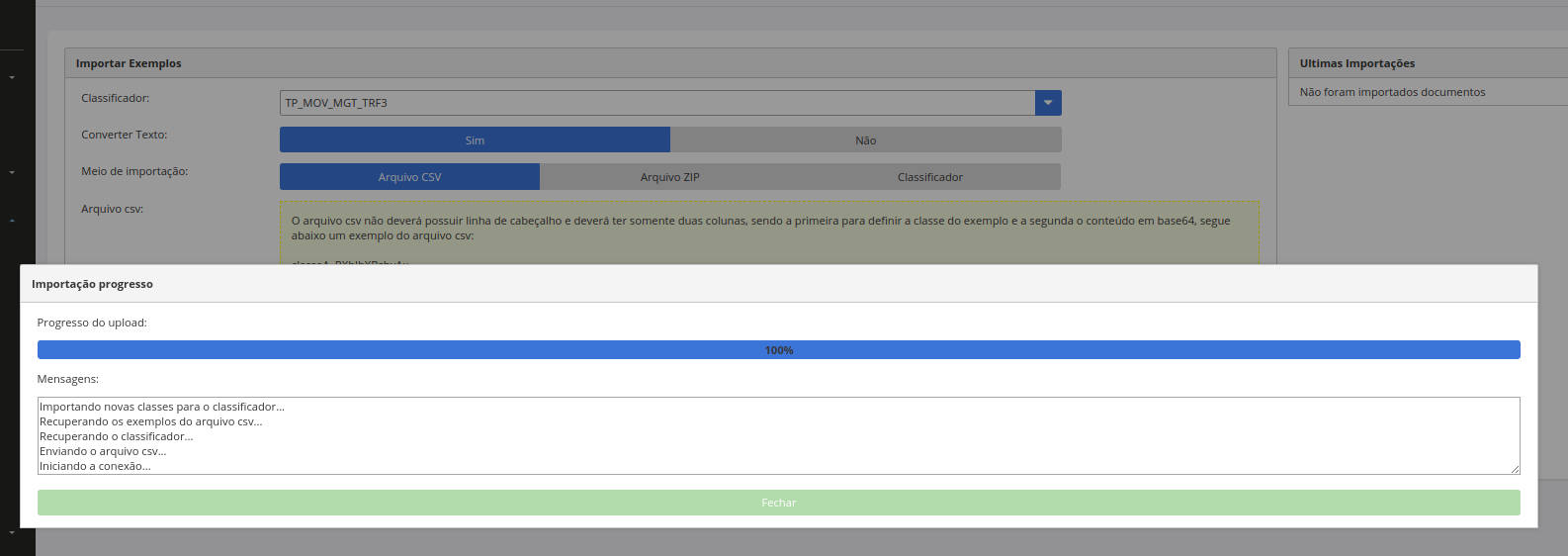
Interface para importar datasets
É possível importar datasets de forma simples, via arquivos CSV, ZIP ou a partir de outros modelos já hospedados. Uma vez importados para um novo projeto, este ficam disponíveis para curadoria ou uso imediato nas futuras versões do modelos.
Tela para importar novos datasets
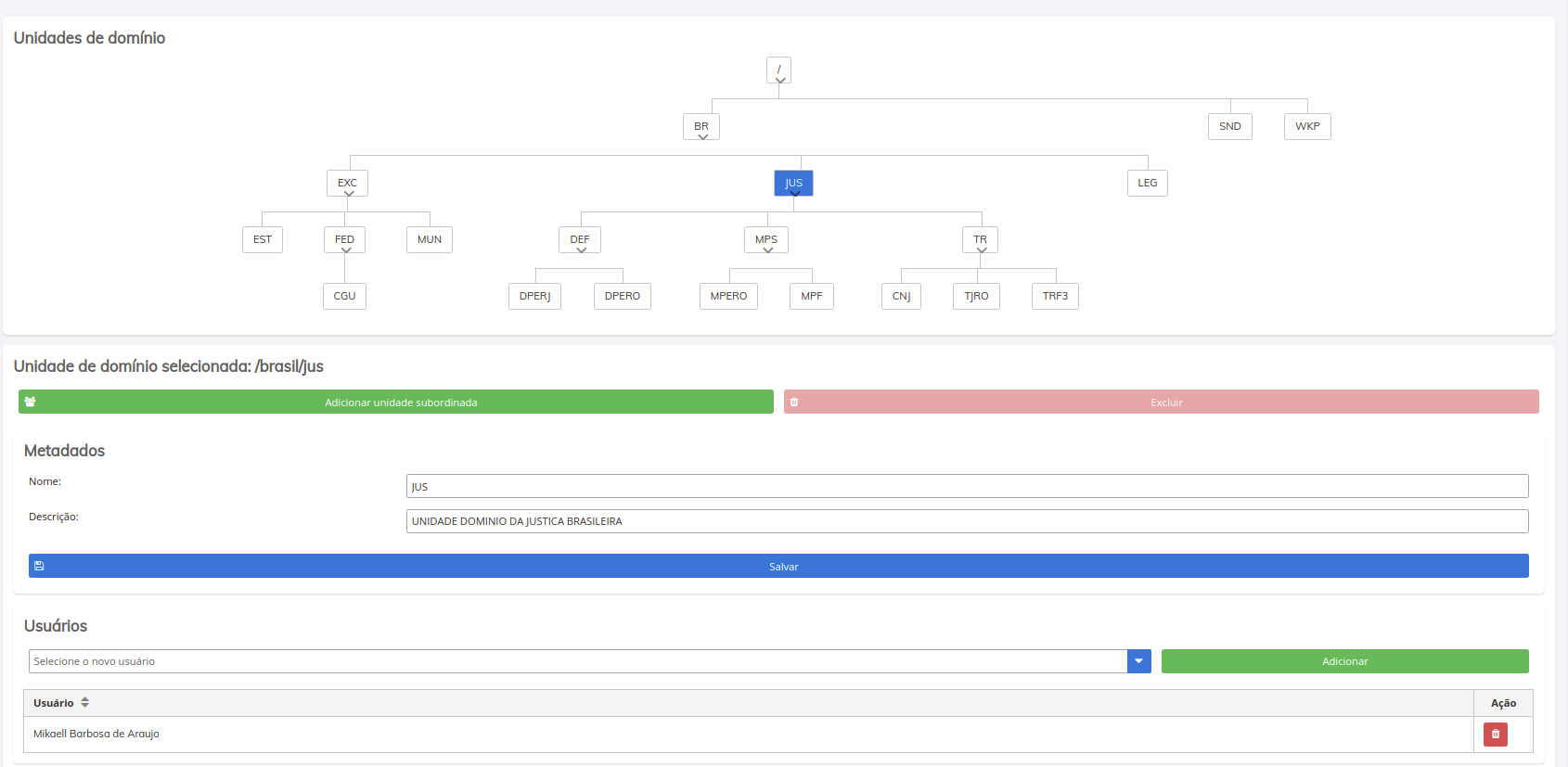
Ambiente Multi-tenant
A plataforma possibilita que cada instituição tenha um ambiente exclusivo para usuários e dados de seu domínio. Embora seja adotada uma política de comunidade, com compartilhamento de conhecimento e algoritmos, essa prática pode ser gerida por cada unidade, conforme política própria para compartilhamento de dados, modelos e pesquisas.
Tela de gestão de domínios
Aprendizado por reforço
A plataforma permite que os sistemas clientes alimentem a base de documentos (para treinamento do modelo) com novos exemplos a partir do uso. Se houver divergência entre a sugestão ofertada pela IA e a escolha do usuário, o documento em questão para esta divergência será armazenado em uma área de “reforço”, registrando o impasse, para que seja resolvido por um terceiro (humano). Após a definição de quem estava certo, o novo exemplo poderá compor uma nova base de treinamento, para uma nova versão do modelo.
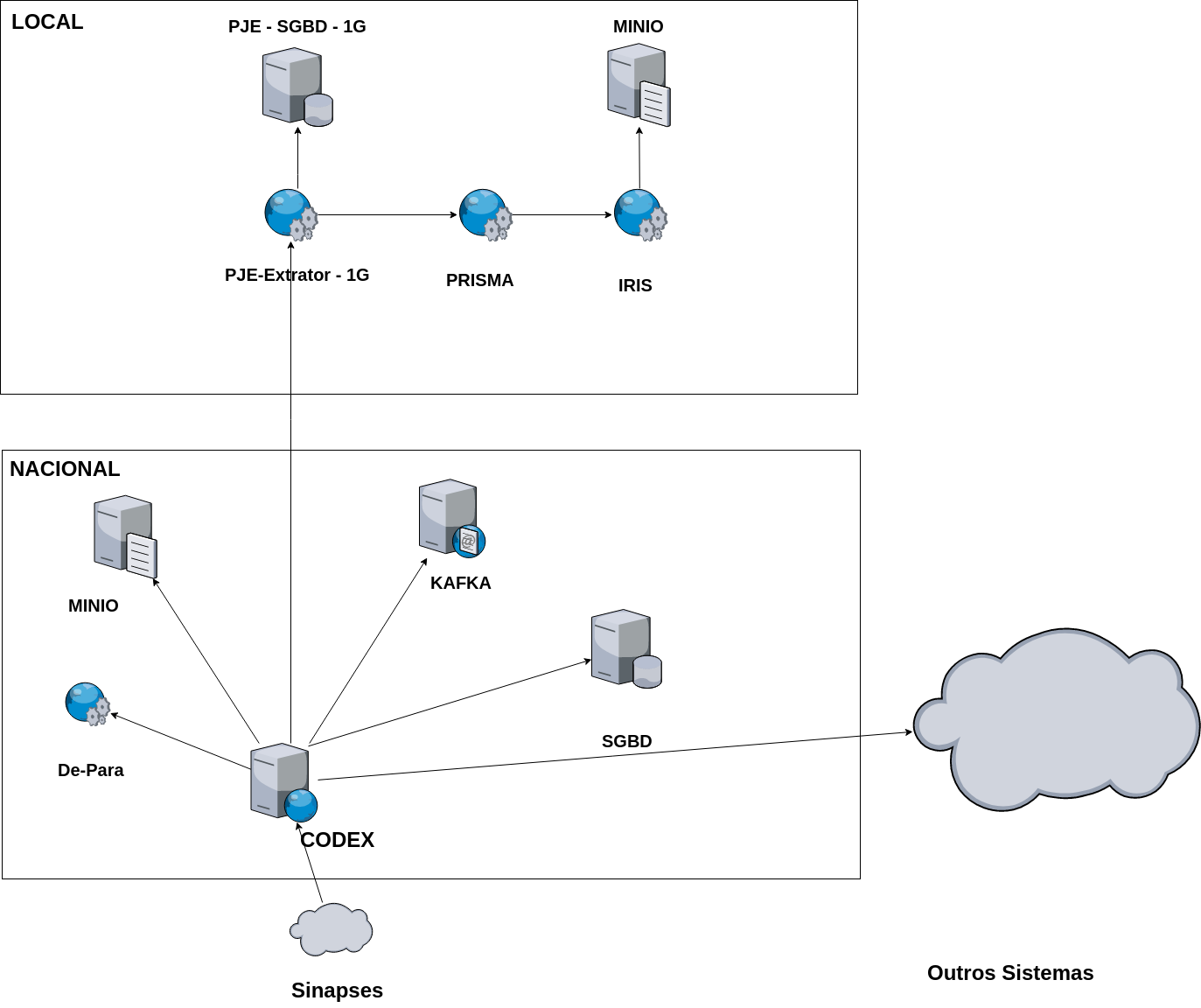
Sistemas que operam em conjunto com o SINAPSES
- Iris: API para OCR de documentos
- Prisma: API para parser de documentos
- Codex: sistema para consolidação de bases processuais, com finalidade de prover documentos estruturados para construção de modelos de IA. Os insumos produzido pelo Codex podem ser utilizados na produção de BI e pesquisa unificada. Este sistema está em fase de homologação, com previsão para entrar em produção até primeira quinzena de dezembro de 2019. Alem de consolidar em texto "puro" os processos, ele também extrai os metadados (partes, dados das partes, quantidade de partes, classe, assunto, valor da causa, número do processo, data de ajuizamento, justiça gratuita, nivel de sigilo, liminar, competência, origem, tipo de justiça, jurisdição, movimentos dos processos). Em média, a cada três segundos os dados são sincronizados com o Codex.
Diagrama de operação
Modelos de Inteligência Artificial
O que é um modelo de inteligência artificial
Abstração de atividades ou rotinas, criada a partir de modelos matemáticos para classificar novas interações com padrões similares (realizar predições).
Um determinado tribunal, selecionou 50 mil petições relacionadas a Energia Elétrica, Companhias Telefônicas, Companhias Aéreas, Bancos, etc. Estas petições foram divididas em cinco grupos, com dez mil exemplos para cada tipo. Esta rotulagem aplicada foi submetida a uma rede neural, criando assim um modelo de IA que é capaz de classificar novas petições semelhantes nestas cinco classes.
Modelos em desenvolvimento
Os modelos abaixo listados estão em desenvolvimento, homologação ou produção, e estarão disponíveis para todos os tribunais que utilizam o PJE, com a finalidade de implementarem automações com uso de Inteligência Artificial ao processo judicial.
Movimento Inteligente
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Movimento Inteligente | O modelo de movimento inteligente tem por finalidade sugerir, em acordo com a TPU, qual o movimento será aplicado no despacho, fazendo uso de inteligência artificial. A API está adaptada para receber documentos, e retornar uma predição do movimento mais provável o mesmo (gratuidade de justiça, mero expediente, concedida medida liminar, etc). | Classificador | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Ativo / Produção | 91% | GIT LIN |
Prevenção
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Prevenção | Varre bases processuais e identifica possíveis casos de prevenção, em acordo com o código civil. | Clustering | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Em testes | Não se aplica | GIT |
Similaridade Processual
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Similaridade processual | Varre bases processuais e identifica similaridade entre documentos, com aplicação na assinatura em lote, identificando a partir de um documento escolhido, quais entre os demais do lote possuem maior similaridade. | Clustering | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Em testes / Homologação | Não se aplica | GIT |
Acordão Sessões
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Acórdão Sessões | Lê, identifica e possibilita extrair partes de uma acórdão, como ementa, relatório e voto. | Classificação e estração de conteúdo | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Ativo / Diponível para uso | 94% | GIT |
Gerador de texto jurídico (auto-complete)
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Gerador de texto jurídico | Produz automaticamente sugestões de palavras (autocomplete) com base no que já foi escrito. | - | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Ativo / Diponível para uso | Não se aplica | GIT |
Sumarizador
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Sumarizador | Produz resumos customizados de textos, reduzindo conforme o parâmetro recebido. | - | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Ativo / Diponível para uso | Não se aplica | GIT |
Triagem de Grande Massa
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Triagem de Grande Massa | Faz a classificação de petições iniciais de acordo com temas pré-estabelecidos (energia, banco, cia aérea, etc) | Classificador | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Ativo / Diponível para uso | 66% | GIT |
Verifica Petição
| Nome | Descrição | Tipo | Tribunal gestor | Reponsáveis | Situação | Acurácia | GIT |
|---|---|---|---|---|---|---|---|
| Verifica Petição | Faz a classificação de um documento, informando se trata ou não de uma Petição Inicial. | Classificador | Tribunal de Justiça de Rondônia | Equipe TJRO: Alcides Fernando, Cleiton Augusto, Felipe Colen, Mikaell Araujo, Pablo Moreira | Ativo / Diponível para uso | 99% | GIT |
Mão na massa
Neste capítulo iremos aprender como criar um modelo de classificação no SINAPSES. O exemplo abordado tem caráter didático, por isso utilizaremos um dataset simbólico, para otimizar o tempo de importação e treinamento.
Pré-requisitos
Para realizar os passos seguintes, é necessário que você tenha conhecimentos suficientes no desenvolvimento de linguagem Python, para lhe auxiliar, indicamos que você realize um dos cursos abaixo, todos gratuitos.
Acessando a SandBox
Credenciais
Criamos um ambiente para que você possa realizar as atividades propostas neste passo a passo. Acesse a ulr https://sinapses-hml.ia.pje.jus.br e faça login com o usuario da sua instituição.
Caso você esteja fazendo o treinamento online, ou apenas deseja acesso para efetuar testes em seu tribunal, siga os passos abaixo para obter seu acesso.
- Acesse a url http://keycloak.ia.cnj.jus.br/auth, e clique em ADMIN CONSOLE conforme a imagem abaixo para ter acesso ao painel de controle do Keycloack.
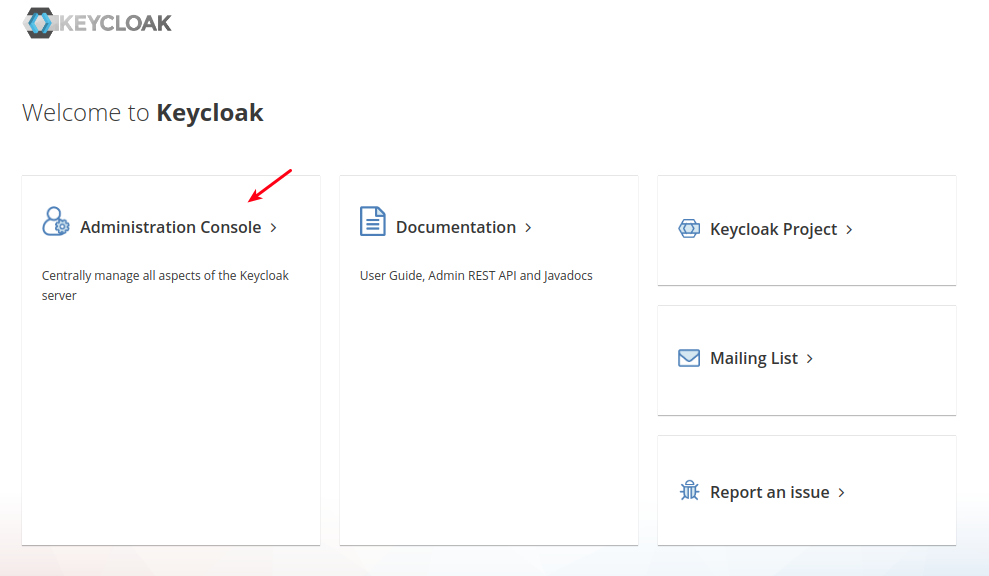
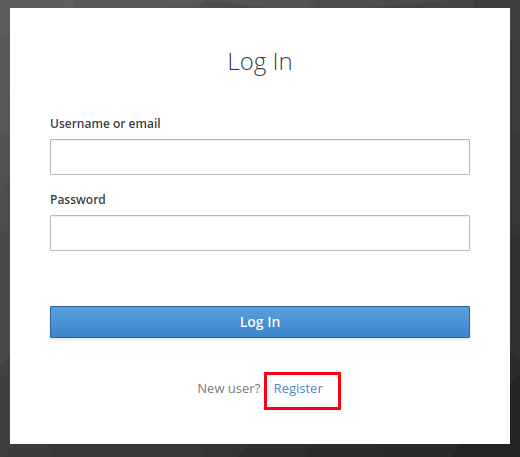
- Clique em register, indicado pelo retangulo vermelho.
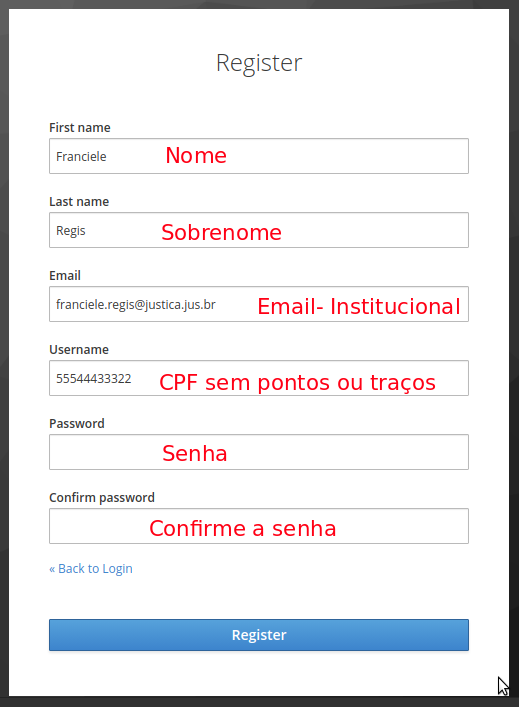
- Preencha os campos, conforme indicado na imagem abaixo. No campo USERNAME, insira seu CPF sem pontos e sem traço.
Uma vez cadastrado, faça conforme abaixo:
- Acesse o SINAPSES: faça seu primeiro logon no SINAPSES, ainda não terá acesso aos recursos, mas isso irá criar suas credenciais na plataforma, só então, após ter efetuado o primeiro logon, siga os passos abaixo.
- Aluno EAD: Solicite o acesso ao DOMINIO EAD, através do suporte do CNJ.
- Acesso via Tribunal: Solicite o acesso ao DOMINIO SANDBOX/SEUTRIBUNAL, através do suporte do CNJ.
Este não é um ambiente de produção, então não utilize com intuito de realizar apresentações ou integrar ao sistema de produção, mas caso faça isso, lembre-se que as atividades realizadas neste ambiente está compartilhando recursos e dados com os demais utilizadores. Se o seu interesse é de imediato colocar em produção um produto, entre em contato com a gestão do CNJ para adquirir um domínio exclusivo para sua instituição em ambiente de produção.
Criando um modelo - Classificador
Basicamente, todos os modelos criados no SINAPSES seguem um pipeline similiar, iremos demonstrar como realizar a criação de um modelo de IA, criando um classificador.
Criando um Classificador
- No menu lateral, clique no menu Classificador/Classificadores.
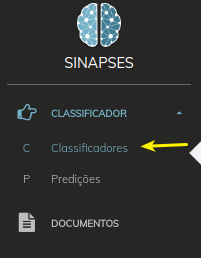
- No rodapé da nova página que abrirá, clique em no botão NOVO.

- A tela abaixo será apresentadada, nela você deverá preencher conforme o seu caso de uso.
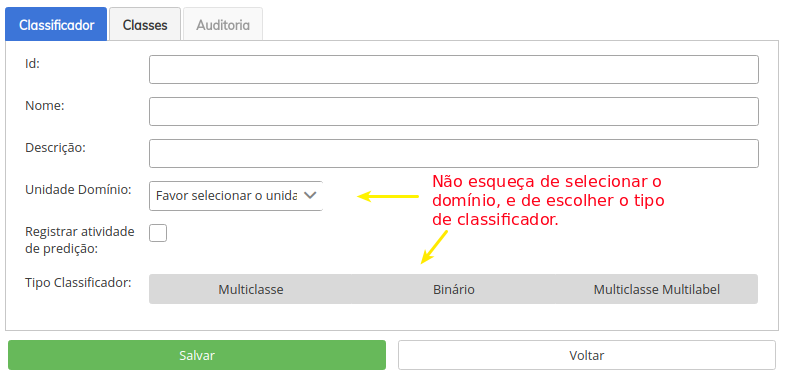
Preenchendo os campos:
- Nome - o sistema automaticamente irá recursar caracteres especiais e espaços, bem como só permitirar caixa alta. Não é permitido dentro da mesma unidade de dominio o mesmo nome para mais de um classificador (este restrição tem por fundamento garantir um único endereço de API por modelo.
- Descrição - preenchimento livre, considere colocar informações relativas ao classificador para sua melhor identificação dentro da plataforma.
- Unidade Domínio - você deverá escolher um dominio (detro dos quais sua conta está inserida) para
- Registrar Atividade de Predição - ao marcar este campo, você está passando a informação para API, que todas as predições serão auditadas, salvando os documentos que foram ofertados em cada predição. Esta função é útil, além da auditoria, para gerar novos exemplos que poderão ser utilizados para apredizado por reforço do modelo. Avalie bem antes de utilizar esta opção.
- Tipo Classificador - escolha conforme o seu caso (esta opção será desabilitada nas próximas versões da interface, e sua resposabilidade ficará a cargo do algortimo do modelo criado).
- Para o nosso exemplo iremos criar um modelo didático, para realizar predições sobre personagens da DC e COMIC, chamaremos este classificador de
CB_PERSONAGENSe será preenchido conforme abaixo. Por questões didáticas, não faremos um exemplo com dados e situações relacionadas ao PJe, pois a maioria destes modelos demanda um tempo signtificativo para treinamento, mas você encontrará na documentação dos modelos ativos, aqui disponível, o passo a passo para criar novas versões dos modelos existentes com uso da base de dados do seu tribunal.
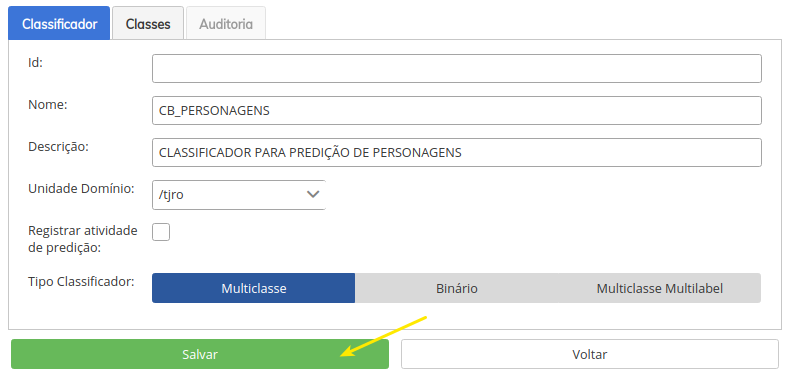
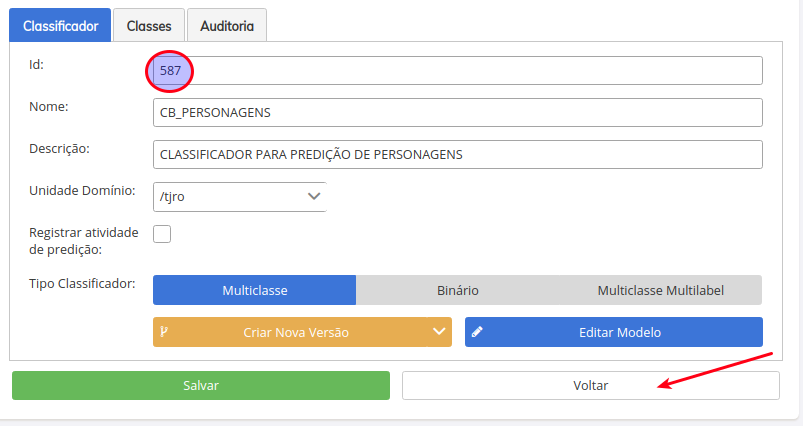
- Estando tudo certo, você receberá uma mensagem de sucesso, e o ID da versão ser aplicado, clique em voltar, e retorne para lista de classificadores de seu dominio.
- No campo nome, realize a pesquisa por seu modelo, e clique em pesquisar, deve retornar conforme a tela abaixo.
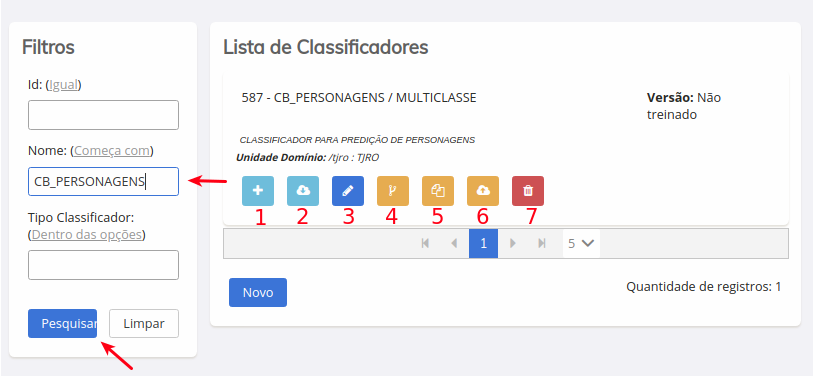
Conforme a numeração da imagem, a função de cada menu é apresentada a abaixo:
-
1 - Cadastrar exemplos - esta é uma foma de você cadastrar exemplos manualmente, um por um para o seu classificador.
-
2 - Importar exemplos em lote - esta opção lhe permite importar exemplos em lotes de arquivos csv ou zip.
-
3 - Editar Classificador - nesta opção você poderá editar e ver maiores informações relacionadas ao seu classificador.a
-
4 - Preparar uma nova versão - irá abrir uma tela para criar uma nova versão do modelo. É necessário que tenham exemplos válidos, do contrário o sistema irá retornar uma mensagem de erro.
-
5 - Duplicar Classificador - escolha conforme o seu caso (esta opção será desabilitada nas próximas versões da interface, e sua resposabilidade ficará a cargo do algorítmo do modelo criado).
-
6 - Exportar Classificador - escolha conforme o seu caso (esta opção será desabilitada nas próximas versões da interface, e sua resposabilidade ficará a cargo do algortimo do modelo criado).
-
7 - Excluir Classificador - Esta opção irá deletar o classificador e todos os exemplos vinculados a ele.
Editando um Classificador
Você pode acessar a edição de um classificador, clicando em EDITAR CLASSIFICADOR, conforme a figura anterior, onde lhe será a apresentada a tela abaixo:
- Nesta tela, é possível alterar as informações do classificador, modificando as funções já demonstradas. Podemos também editar a versão do modelo associada ao classificado (caso ela já exista); visualizar, editar, excluir ou incluir novas classes; ver informações de auditoria do classificador.
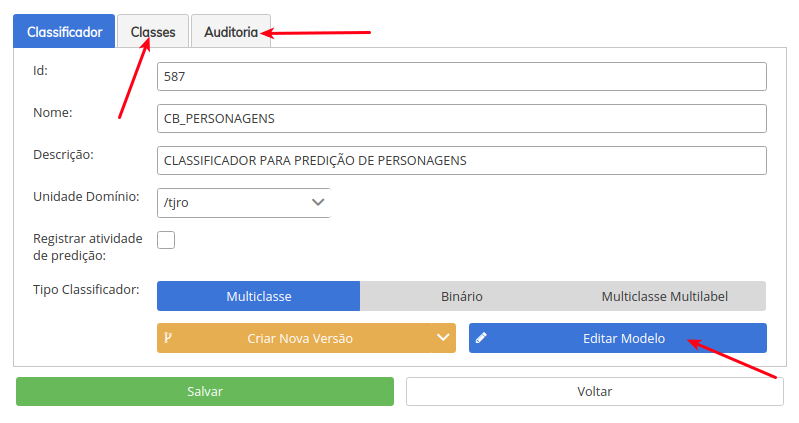
- Na aba Auditoria estão informações de criação e alterações sofridas pelo classificador.
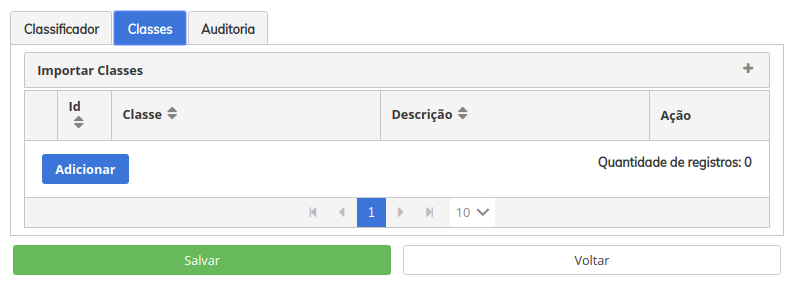
- Classes (rótulos ou labels). Quando criamos um modelo para classificação, necessitamos definir rótulos/labels para os documentos que serão utilizados no apredendizado supervisionado. Embora você possa futuramente se deparar com modelos que usam rótulos da TPU (Classes e Assuntos), esta vinculção não possui correlação com a mesma, por regra chamamos classes, mas pode ser entendido como rótulo, tags ou saídas. Na imagem abaixo, nosso classificador está sem nenhuma classe, pois ainda não criamos nenhuma. Podemo criar as classes que iremos utilizar, ou, ao importar nossos exemplos, definir no arquivo de importação estas classes já vinculadas aos exemplos, isso fará com que o SINAPSES crie automaticamente estas classes para o classificador.
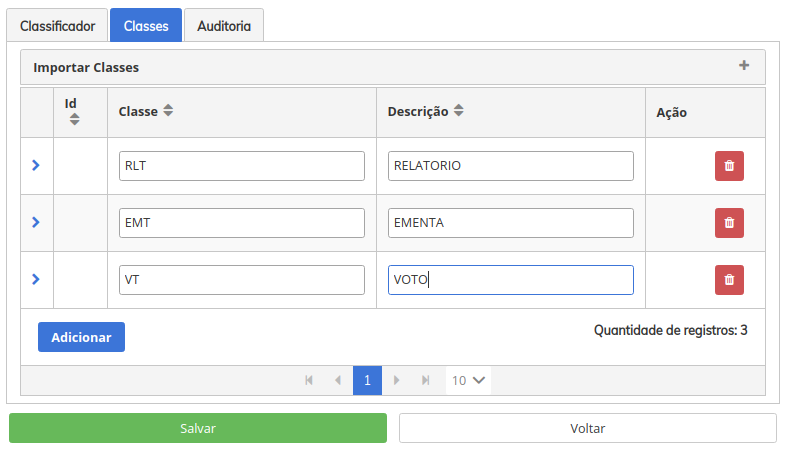
- Na imagem abaixo, fizemos a inclusão de algumas classes. A descrição da classe, será o rótulo ofertado pela predição quando a API do modelo for requisitada. Você pode incluir quantas classes desejar, de acordo com os exemplos que tem disponíveis para cada uma delas. Vale ressaltar que você também poderá excluir os rótulos, porém se houverem exemplos associados, eles também serão excluídos. Isso as versões dos modelos já treinados, porém irá impactar nas próximas versões geradas.
- Se você clicar no menu EDITAR MODELO, irá ser apresentada a tela abaixo, e poderá observar que ainda não existe nenhuma versão de modelos criadas, pois é o que faremos nos próximos passos, criar uma nova versão de um modelo para o classificador. No SINAPSES podemos ter várias versões treinadas(ativas ou não) para um classificador.
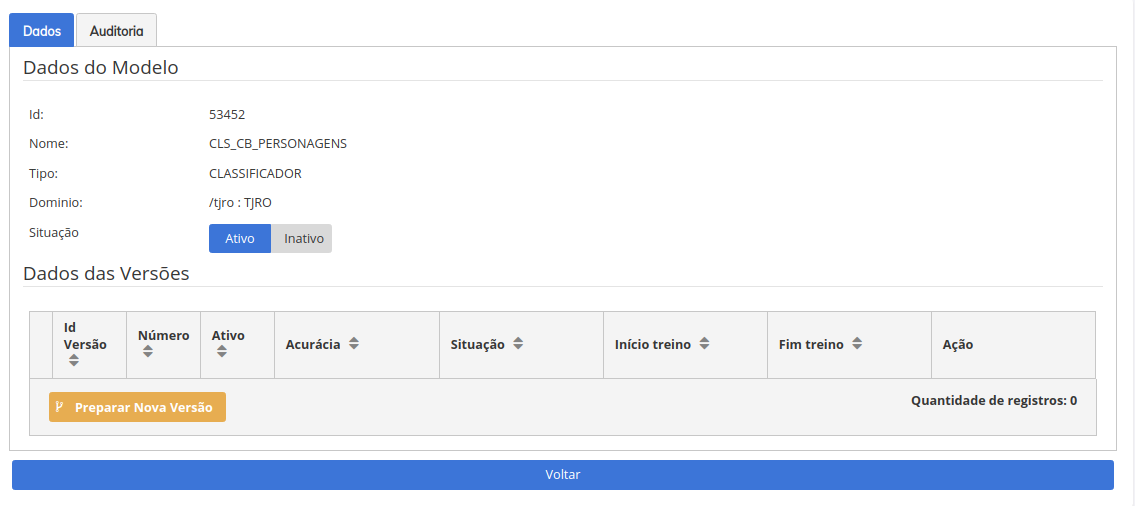
Importando Exemplos
Neste topico iremos aprender como importar exemplos para o nosso classificador, atividade esta que pode ser realizada de três formas, como já citado anteriormente, a maneira que você irá utilizar irá depender da comodidade e habilidade no manuseio dos seus dados. Na seção Cookbook, estaremos disponibilizando scripts prontos para a maioria dos modelos já homologados, facilitando este processo para você.
Importando um a um:
Para este método, é preciso antes criar as classes que irão receber os exemplos, então realize os seguintes passos:
a. Pesquise pelo seu modelo, conforme descrito na Figura 22, e clique no ícone indicado pelo número 3(caneta), depois vá na aba classes, conforme a figura 25, e clique em adicionar, coloque o nome que desejar, depois clique em salvar. Clique em voltar
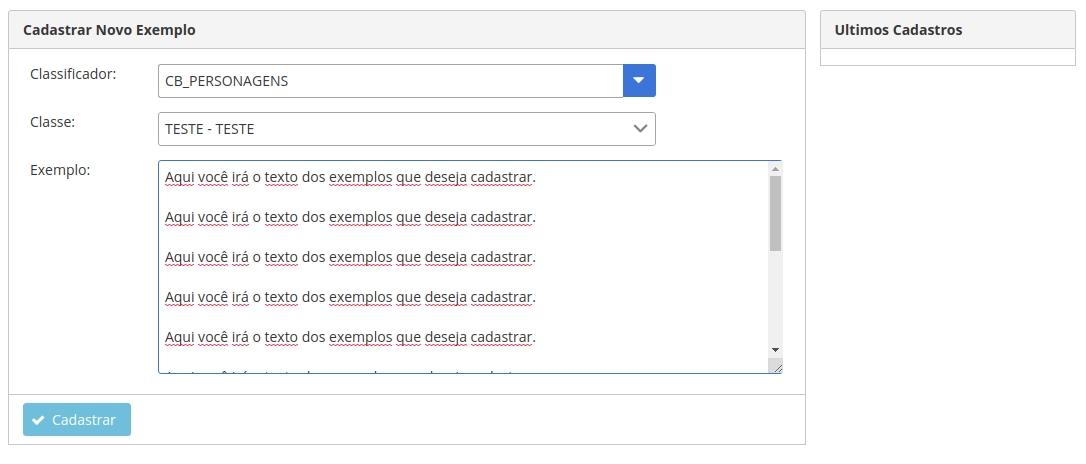
b. Pesquise pelo seu modelo, conforme descrito na Figura 22, e clique no ícone indicado pelo número 1(sinal de mais). A tela abaixo será apresentada.
c. Selecione uma classe e cole o texto que deseja inserir, depois clique em CADASTRAR.
Importando em lote - arquivo CSV:
Antes de iniciar este método, delete a classe criada no exemplo anterior, ela não será necessária para nosso modelo. Feito isto, siga os passos abaixo:
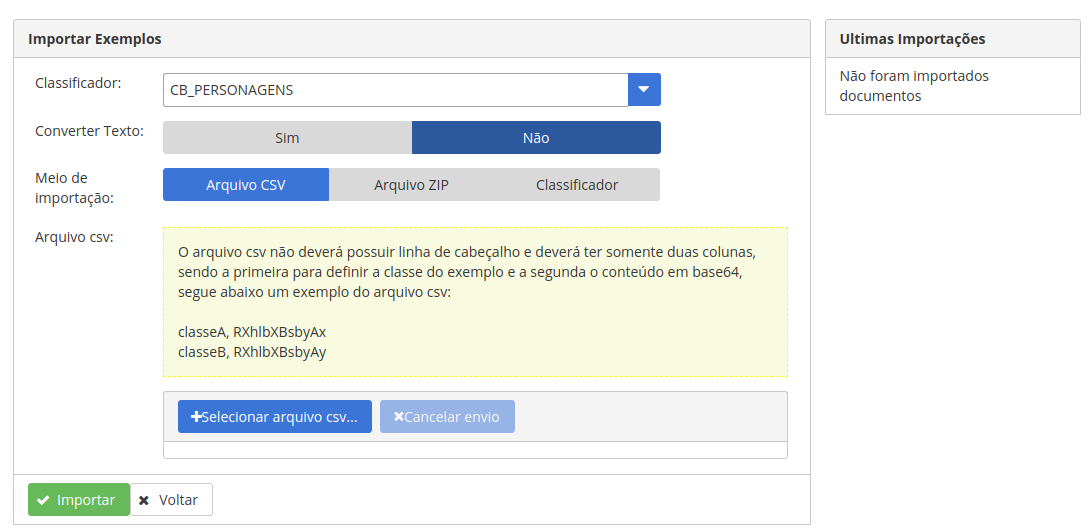
a. Pesquise pelo seu modelo, conforme descrito na Figura 22, e clique no ícone indicado pelo número 2(sinal de nuvem). A tela abaixo será apresentada.
b. Na opção CONVERTER TEXTO, clique em NÃO (quando usar documentos que possuam marcação html, utilize SIM). O conversor realiza limpeza de textos com tags html, deixando texto puro.
c. MEIO DE IMPORTAÇÃO, selecione ARQUIVO CSV
d. Faça o download do arquivo de exemplo, disponível na url DATASET01 logo abaixo.
e. Clique em SELECIONAR ARQUIVO CSV e depois em IMPORTAR, aguarde até receber uma mensagem de confirmação positiva.
Importando em lote - arquivo ZIP:
Você também pode utilizar arquivo zip para importar seus datasets, esta é a forma mais prática para grandes quantidades de dados. Os script do CookBook irão ofertar este formato de entrada.
a. Pesquise pelo seu modelo, conforme descrito na Figura 22, e clique no ícone indicado pelo número 2(sinal de nuvem). A tela abaixo será apresentada.
b. Na opção CONVERTER TEXTO, clique em NÃO (quando usar documentos que possuam marcação html, utilize SIM). O conversor realiza limpeza de textos com tags html, deixando texto puro.
c. MEIO DE IMPORTAÇÃO, selecione ARQUIVO CSV
d. Faça o download do arquivo de exemplo, disponível na url DATASET01 logo abaixo.
e. Clique em SELECIONAR ARQUIVO CSV e depois em IMPORTAR, aguarde até receber uma mensagem de confirmação positiva.
Verificando Exemplos Importados
Após ter importado nossos exemplos, podemos verificar a efetividade do processo seguindo os passos abaixo, além de outras atividades que podem ser realizadas de acordo com os casos elencados a seguir. Um ponto importante a ser frisado, a plataforma faz o controle por hash de conteúdo dos arquivos, ou seja, não teremos arquivos duplicados. Quando um exemplo é inserido, e o mesmo já está armazenado, ele apenas será indexado.
Nos dois menus indicados na imagem abaixo, você poderá manipular os exemplos inseridos.

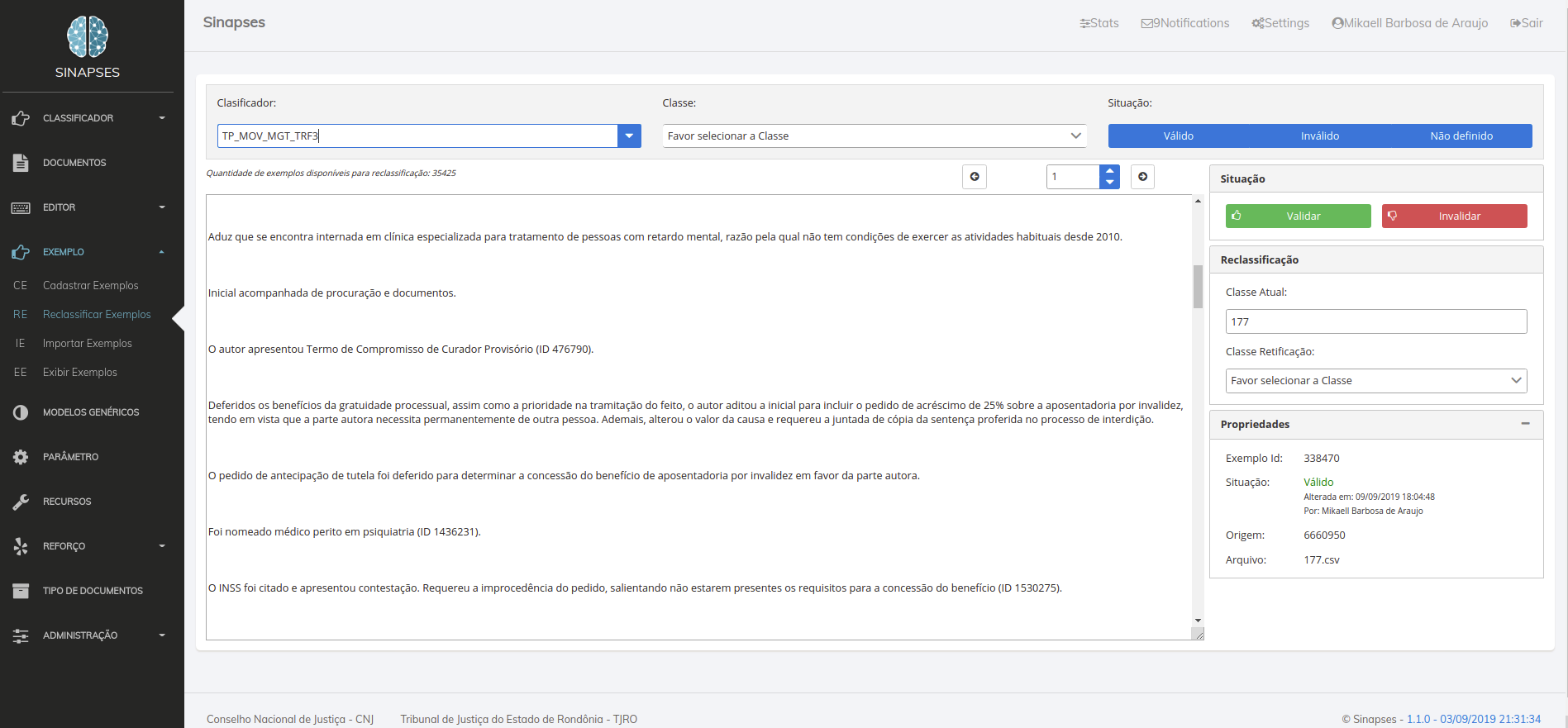
Reclassificando exemplos
A reclassificação de exemplos é utilizada pela atividade de curadoria para validar, invalidar exemplos, processo chamado de "aprendizado supervisionado. Uma vez finalizada a atividade de curadoria, os exemplos válidos estão aptos a serem utilizado no dataset de treinamento do modelo.
Em ambiente de produção, um perfil TREINADOR é ofertado às equipes de negócio, para realizarem o processo de aprendizado supervisionado dos modelos.
As considerações necessárias para esta tela, são feitas logo abaixo, de acordo com a imagem abaixo:
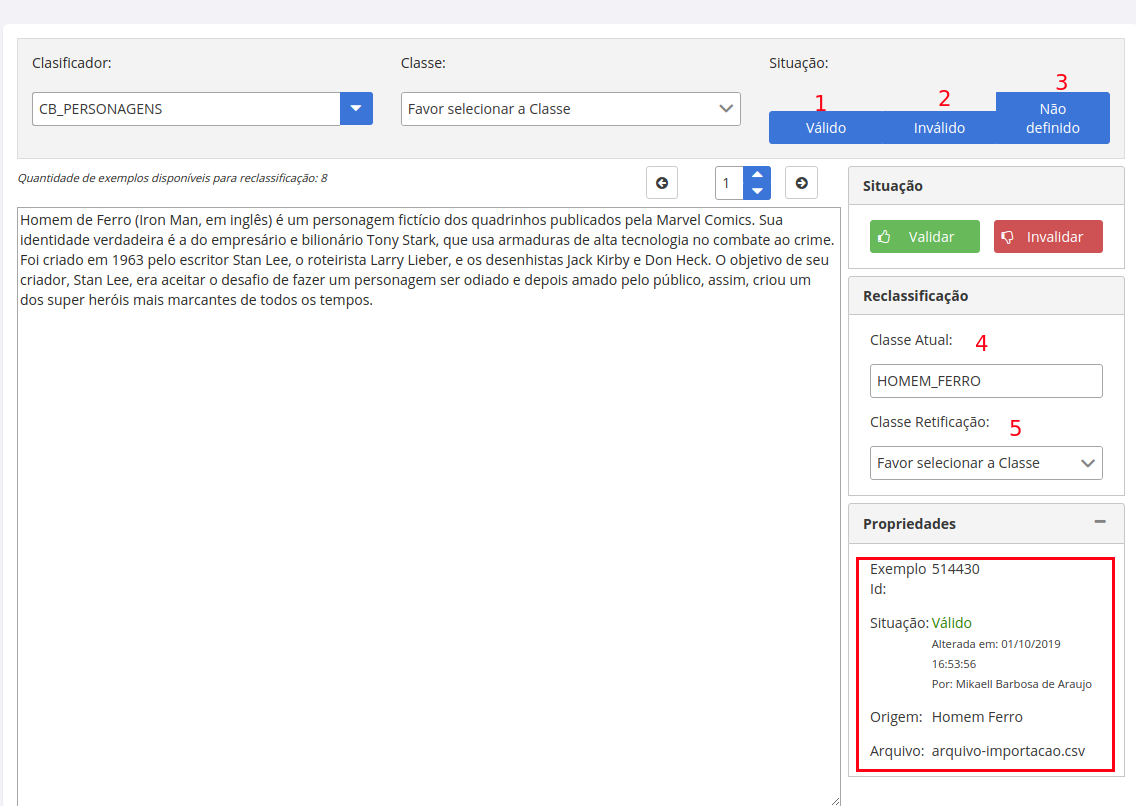
Os exemplos podem ser divididos em 3 estados:
- Valido - cenário ideal, os documentos passaram pelo processo de curadoria, ou já foram validados em lote previamente, e estão aptos para compor o dataset das versões a serem preparadas do modelo.
- Invalido - são documentos que passaram pelo processo de curadoria, e por algum motivo, conforme a regra de negócio acertada entre a equipe, o documento não possui os critérios ou qualidade necessária para ser inserido no dataset, então o mesmo será invalidado. Durante o processo de raspagem de dados, é comum algum lixo vir juntamente com os demais documentos, por isso a necessidade de um processo minucioso de curadoria ser realizado antes da utilização desta base de dados.
- Não definido - são documentos que foram inseridos e aguardam o processo de curadoria, caso você tente gerar uma versão para o modelo, e todos os seus documentos estejam neste estágio, uma mensagem de erro será apresentada.
O processo de reclassificação, além da validação, consiste também em, aplicar, confirmar ou retificar os rótulos/labels/classes aplicados a cada documento. O curador, ao ler o documento, poderá realizar esta atividade (indicado pelos número 4 e 5), garantindo um dataset de qualidade. Uma outra vantagem em utilizar o SINAPSES para esta atividade, é que este processo é realizado com grande rapidez e intuitividade, após validar ou invalidar o documento, o próximo será lançado em tela, e assim sucessivamente até a total curadoria de toda base.
PS: Está no backlog, para versões futuras do SINAPSES, a possibilidade de realizer um double check, onde a validação ocorrerá através da validação por dois curadores, e na ocorrência de divergências na validação de um documento, ester será ofertado a um terceiro curador para desempate. Isso trará uma qualidade ainda maior ao processo de aprendizado supervisionado.
Gerando uma versão do modelo
Importamos o nosso modelo, já reclassificamos ou verificamos que nossos documentos estão com a qualidade necessária, então é a hora de prepararmos uma versão do nosso modelo, a primeira versão.
Volte novamente a tela de CLASSIFICADORES, pesquise por seu modelo e clique no ícone conforme a imagem abaixo:
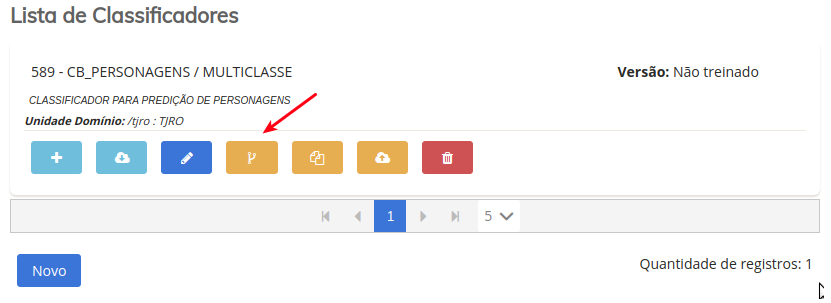
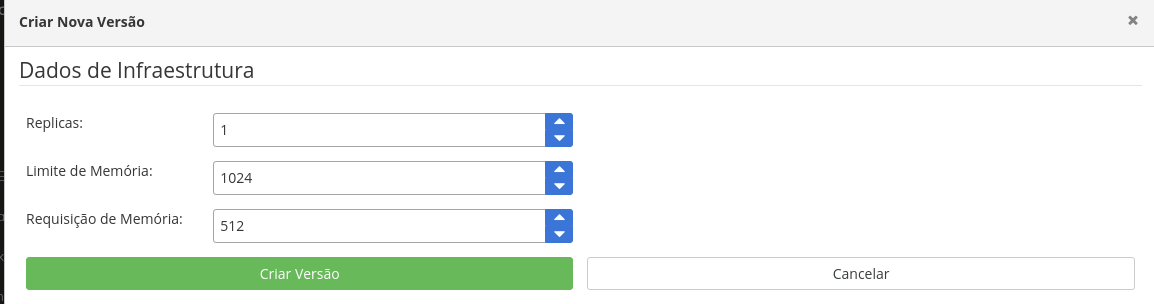
A tela abaixo lhe será apresentada, é nela que você irá definir quantas replicas o seu modelo terá em produção, e a quantidde de memória de cada pod. Não altere nada, para nosso exemplo, apenas confirme clicando em Criar Versão.
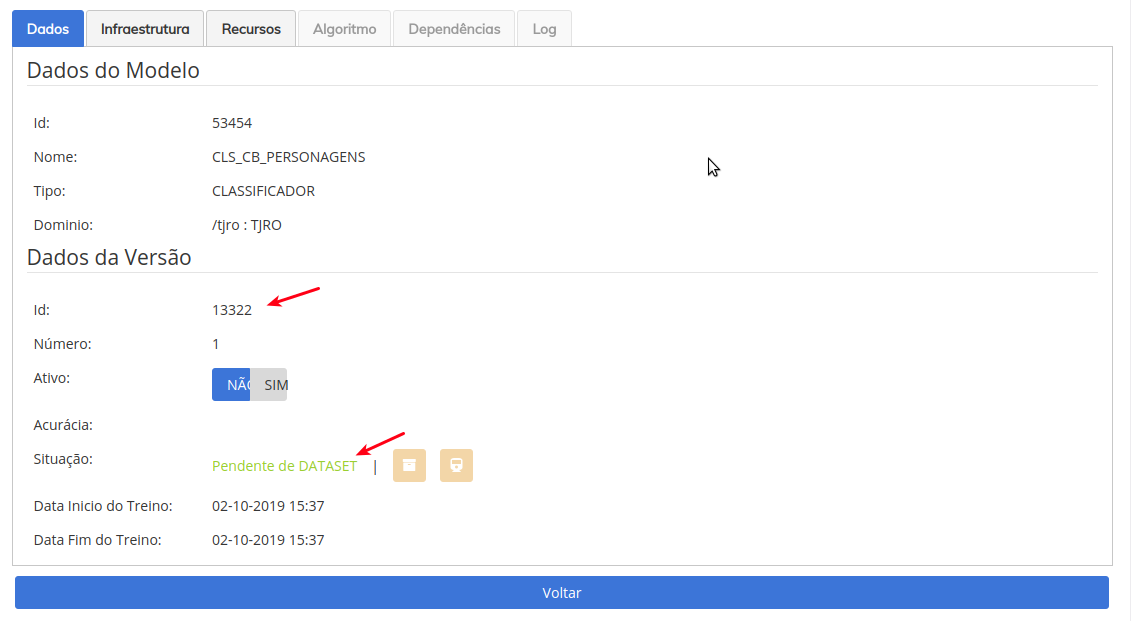
Após clicar, o processo de preparação da versão será iniciado, o mesmo pode demorar um pouco, a depender da quantidade de exemplos. Ao final do processo, a tela abaixo será mostrada. Anote o ID da versão, indicado pela seta, pois o utilizaremos nas próximas etapas. A outra seta está apontando para a SITUAÇÃO, que está setada como "Pendente de Dataset".
Atualize sua tela (F5), e a SITUAÇÃO deverá estar setada como "PENDENTE DE ALGORITMO".
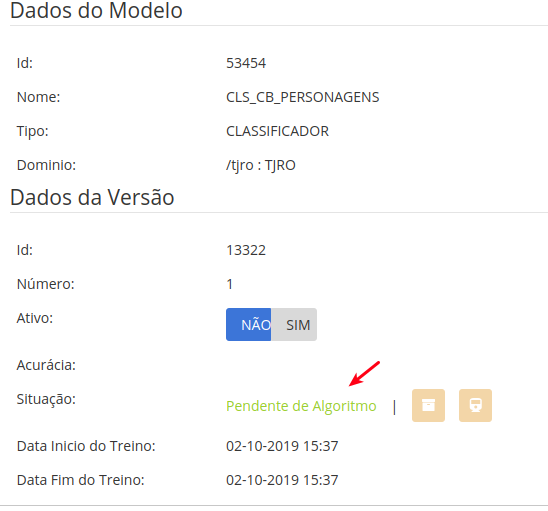
Na aba recursos, os arquivos do DATASET já deverão estar disponíveis.
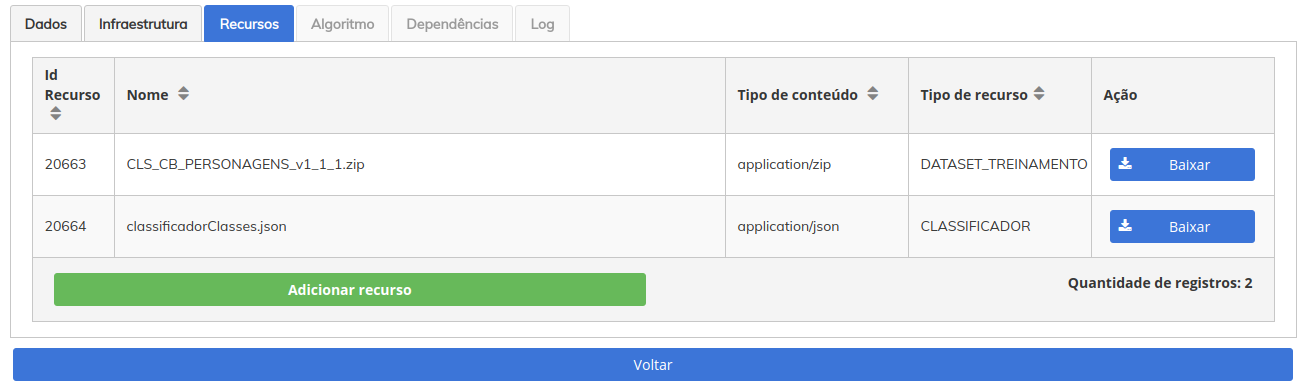
Para chegarmos a tela de gerenciamento de versões, apresentada abaixo, siga clicando em CLASSIFICADORES , pesquise por seu modelo, e clique em EDITAR CLASSIFICADOR (icone da caneta), depois clique em EDITAR MODELO.
Conforme novas versões forem sendo criadas, você poderá gerir cada uma delas a partir desta dela, por padrão, caso você não defina, o sistema irá ativar apenas a versão com maior acurácia, ainda que novas vesões sejam treinadas, mas você pode ativar manualmente e manter em operação mais versões.
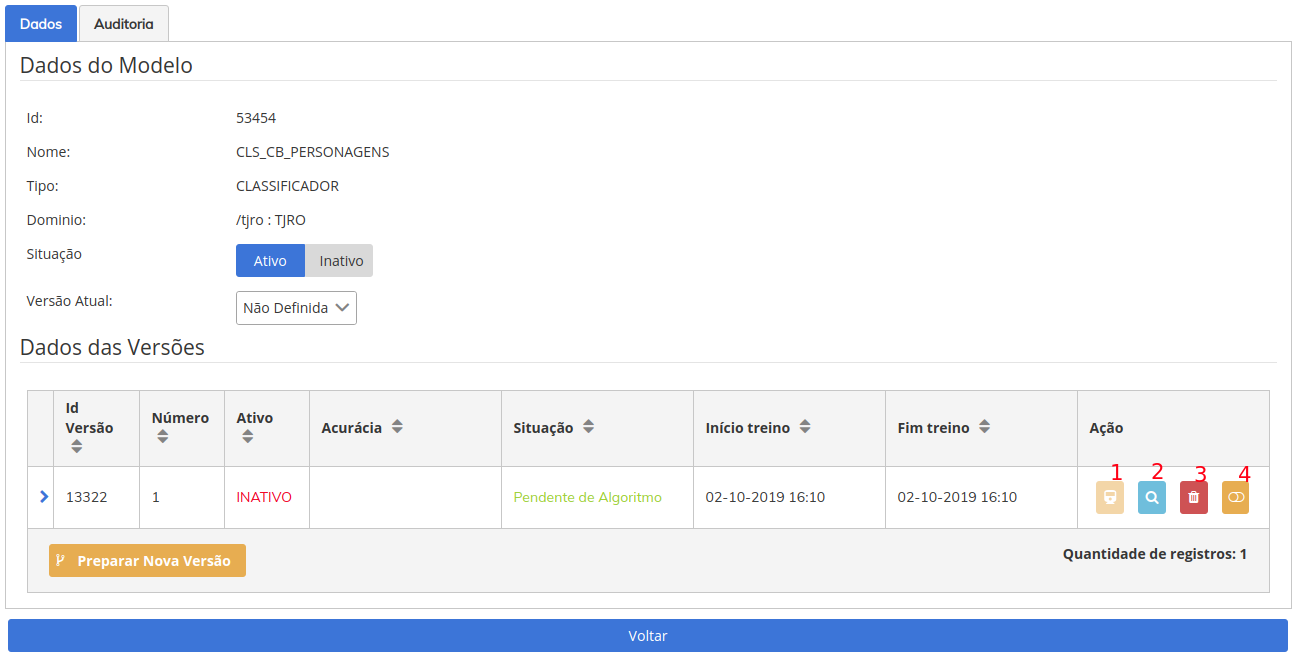
Os botões, conforme a numeração:
- Reiniciar Treino - é possível reiniciar o processo de treinamento em caso de falha.
- Visualizar Versão - são apresentadas informações avanças da versão (algoritmo, recursos, dependências, logs)
- Excluir - para excluir a versão.
- Ativar versão - ativação e desativação manual da versão do modelo. Isso irá desabilitar a API que cada versão possui para ser consumida pelos sistemas clientes.
Treinamento o modelo
Para treinarmos modelos no SINAPSES, podemos utilizar duas formas:
IDE Eclipse ou Console Shell - é a maneira mais indicada, pois permite o debug do código.
Jupyter Notebook - costuma ser o padrão entre cientistas de dados, mas não é mais trabalhoso para debug de erros.
As duas formas estão estáveis para uso atualmente, mas somente o treinamento via IDE sofrerá evoluções futuras no tocante a possibilidade de fazer o deploy do modelo já treinado, sem a necessidade do pipeline de treinamento na plataforma.
Dependências de ambiente
Para treinarmos nosso modelo, necessitamos configurar o nosso ambiente, o que faremos nos passos seguintes. Por padrão, estes passos foram homologados em Sistema Operacional Linux, mas você pode adapta-lo ao Windows, porém não terá suporte aos erros que surgirem, então nossa recomendação é que utilize o Linux como sua base para desenvolvimento e treinamento dos modelos. Em nossos exemplos, utilizamos o Ubuntu 18 LTS.
Instalando o pyenv
O modo mais indicado para trabalhar com o ambiente de desenvolvimento em python, é utilizar o pyenv. Tomaremos como verdade que você já possui conhecimentos suficientes em Linux e na instalação de pacotes, mas abaixo indicamos alguns artigos para lhe auxiliar nesse processo.
Com o pyenv instalado, abra um terminal shell e execute os comandos abaixo:
cd ~
pyenv install 3.6.8
pyenv virtualenv 3.6.8 cranium
pyenv activate cranium
A sua tela deve estar semelhante (o usuario e nome da máquina irão estar de acordo com a sua configuração local) a imagem abaixo, do contrário, revise novamente os procedimentos.
![]()
Temos agora um ambiente isolado, para que possamos trabalhar sem interferir e sem interferências do nosso sistema operacional. Precisamos ainda configurar o PIP apontando para o Nexus do CNJ e instalar as dependências.
Configurando o PIP e atualizando o Ambiente
Necessitams alterar a configuração do PIP para buscar os pacotes no repositório do CNJ, para isso, execute os comandos abaixo conforme indicado ou faça a adptação necessária ao seu sistema operacional.
-
Faça o download do arquivo
pip.conf(disponível no link abaixo) e salve no diretório~/.config/pipCom o botão direito do mouse sobre o link abaixo, escolha Salvar link como...
-
Faça o download do arquivo
requirements.txt, que possui as dependências do nosso ambiente.Com o botão direito do mouse sobre o link abaixo, escolha Salvar link como...
-
No mesmo direitório em que fez o download do arquivo requirements.txt execute os comandos abaixo:
Se for utilizar o
jupyter-notebook:pip install -r requirements.txt
pip install sinapses-nbextension
pip install jupyterSe for utilizar o Eclipse:
pip install -r requirements.txtSe tudo estiver corretamente configurado, irá instalar as dependências necessárias ao ambiente para treinamento (local) e deploy nosso modelo.
Jupyter Notebook - Algoritmo
Com nosso ambiente configurando, já podemos treinar nosso modelo, utilizando o algoritmo que desenvolvemos. O SINAPSES só possui uma restrição em relação ao desenvolvimento de modelos, é necessário utilizar linguagem Python, mas o Cientista de Dados possui total liberdade (ancorado nesta restrição) para desenvolver seus modelos utilizando qualquer framework de IA.
Iremos utilizar o jupyter notebook, mas antes, faça o download do algoritmo no link abaixo:
-
Com o Pyenv instalado, abra um terminal shell e execute os comandos abaixo na mesma pasta onde realizou o download do algoritmo:
pyenv activate cranium
jupyter-notebookSerá aberta uma nova janela no seu navegador, conforme a imagem abaixo (use o Chrome).
-
Vamos agora à execução do algoritmo, clique no arquivo
comic_book_jupyter.ipynb, um nova janela será aberta, com o arquivo diponível para execução.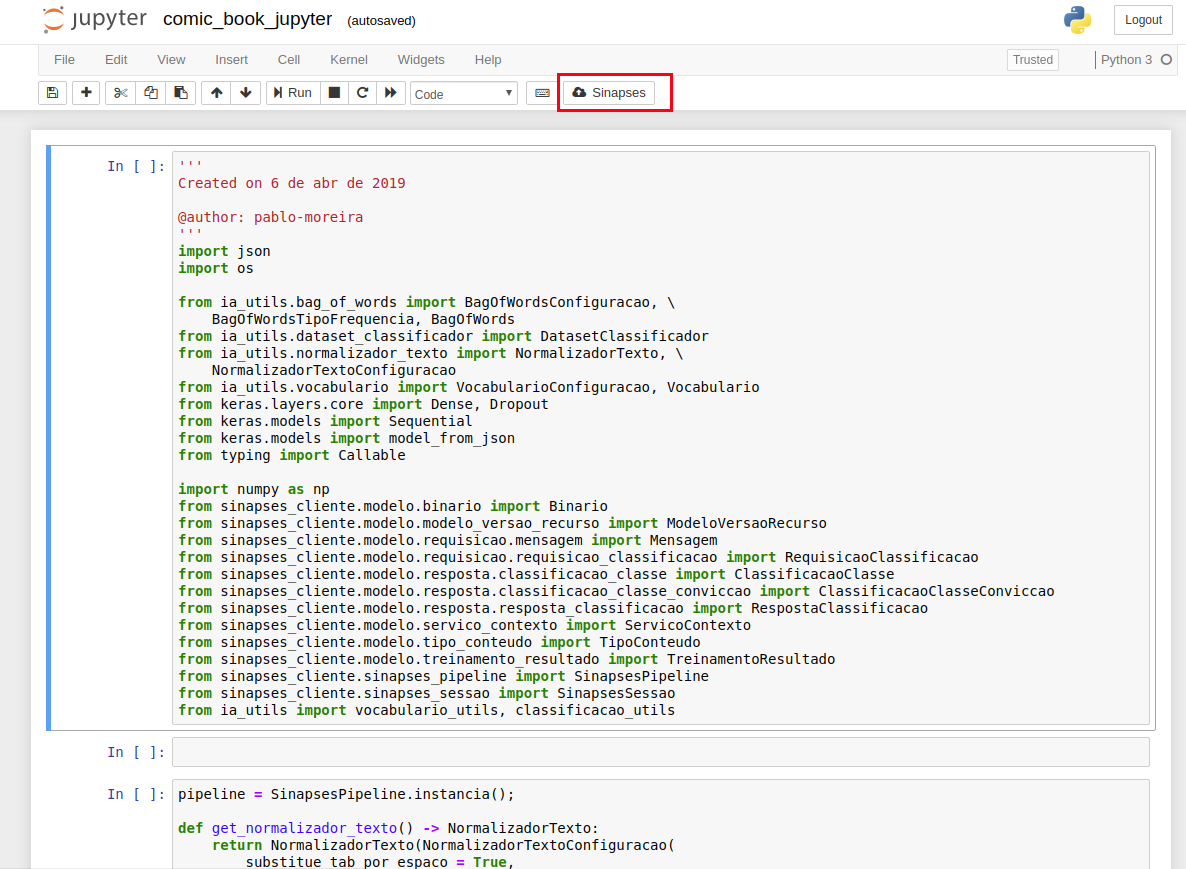
Verique se o botão SINAPSES está disponível na sua interface, caso não esteja, reveja os passos de instalação das dependências do arquivo
requirements.txt. -
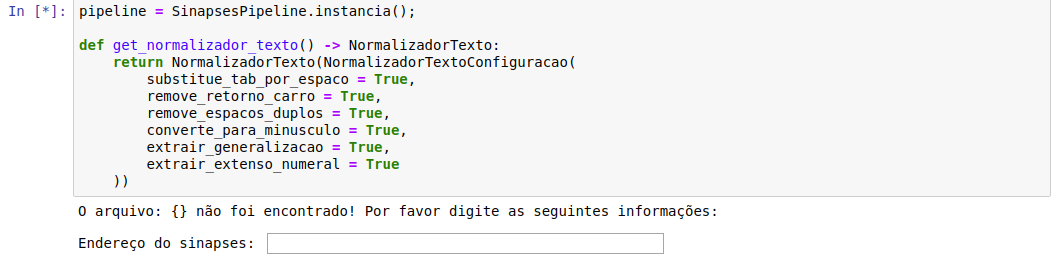
Ao iniciar a execução das celulas, já na segunda tela, você deverá inserir algumas informações:
-
a primeira será o endereço do SINAPSES, digite https://sinapses-backend-hml.ia.pje.jus.br/rest;
-
a segunda será seu usuário, o mesmo com qual acessa o SINAPSES;
-
a terceira será a senha, a mesma de acesso ao SINAPSES;
-
e por ultimo, o ID do modelo, que mostramos anteriormente.
-
-
Continue com a execução das células do notebook, até chegar na ultima célula, onde econtrará a função
pipeline.executar_teste(), ela serve como um pré-teste antes do envio do algorítmo para o SINAPSES. Execute esta também, e verifique se a tela apresentada é semelhante a apresentada abaixo: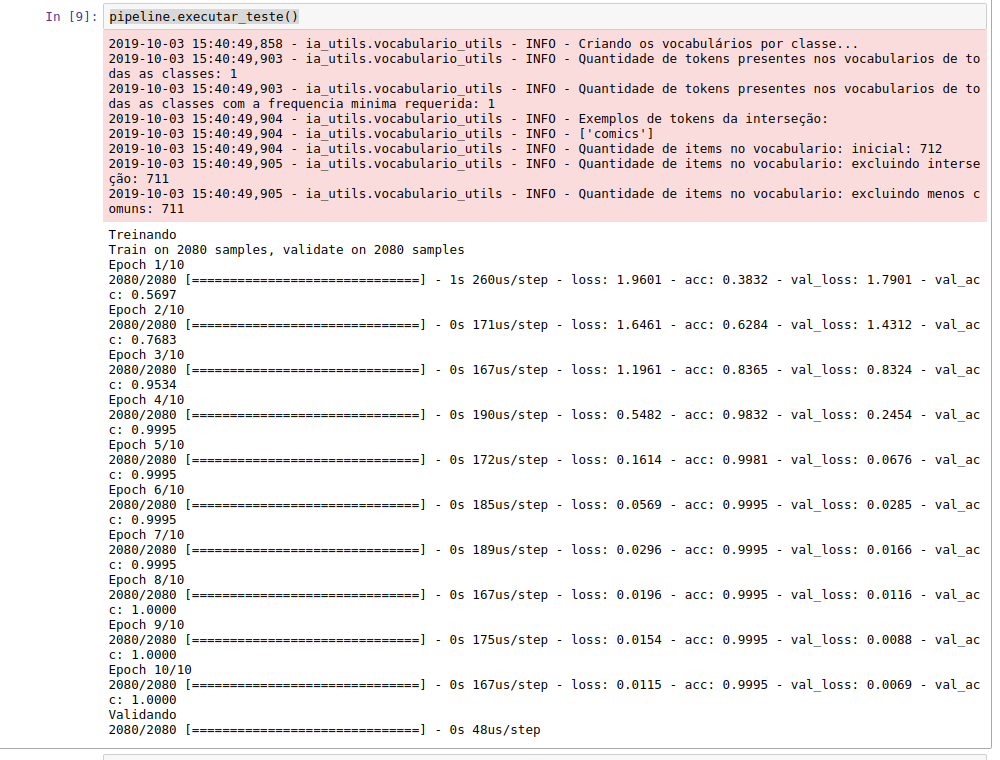
-
Neste ponto, já realizamos o treinamento do modelo em nossa máquina, e certificamos que ele está sem erros, agora podemos realizar o deploy no SINAPSES, para isso, comente a função
pipeline.executar_teste(), conforme a imagem abaixo:
-
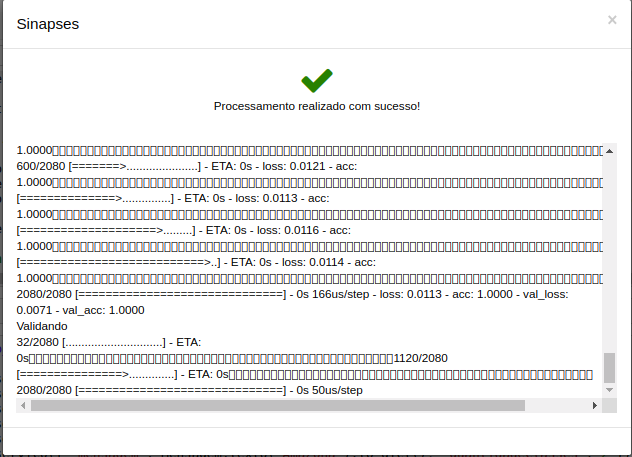
Para realizar o deploy no SINAPSES, clique no botão SINAPSES, no centro do menu.

-
Um dialog será aberto, e irá executar um novo pré-treinamento, conforme a tela abaixo, antes de enviar para o SINAPSES.
-
Vamos voltar agora a tela do nosso modelo, e verificar o estado da nossa versão.
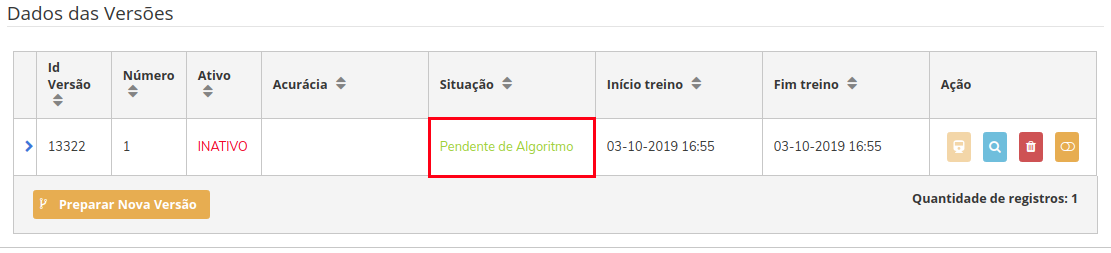
Na imagem acima vemos que, antes do deploy, nossa versão estava Pendente de Algoritmo.
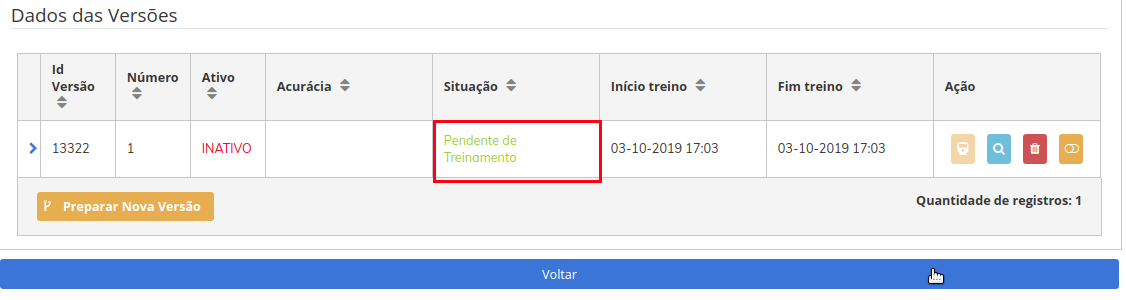
E agora, após o deploy, nossa versão está Pendente de Treinamento.
Aqui é necessário explicarmos, pois certamente você desve estar se perguntando:
"Mas eu já não treinei o meu modelo?".
Sim, verdade, você já treinou, mas em sua estação. No SINAPSES, quando fazemos o deploy, estamos enviando o algoritmo e as dependências do nosso ambiente local, e um novo processo de treinamento será realizado em um pod exclusivo, com as mesmas configurações do seu ambiente local, porém utilizando os recursos da infra-estrutura no qual o SINAPSES está abrigado. Há no backlog, a implementação de possibilitar que esse pipeline possa ser opcional, efetuando o deploy completo dos pesos a rede neural treinada localmente e demais recursos, possibilitando a liberação direta do serviço.
-
Se formos até os logs da nossa versão, poderemos ver o pod
cranium-trnde treinamento sendo criado, até finalizar o processo de treinamento.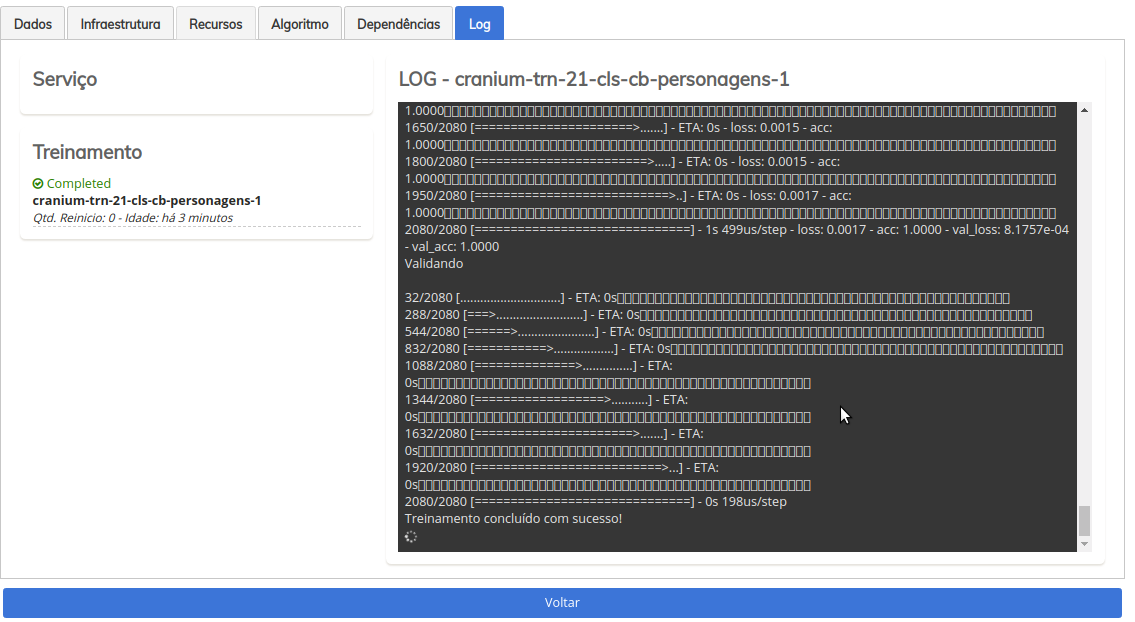
Na tela acima, podemos acompanhar o treinamento do modelo.
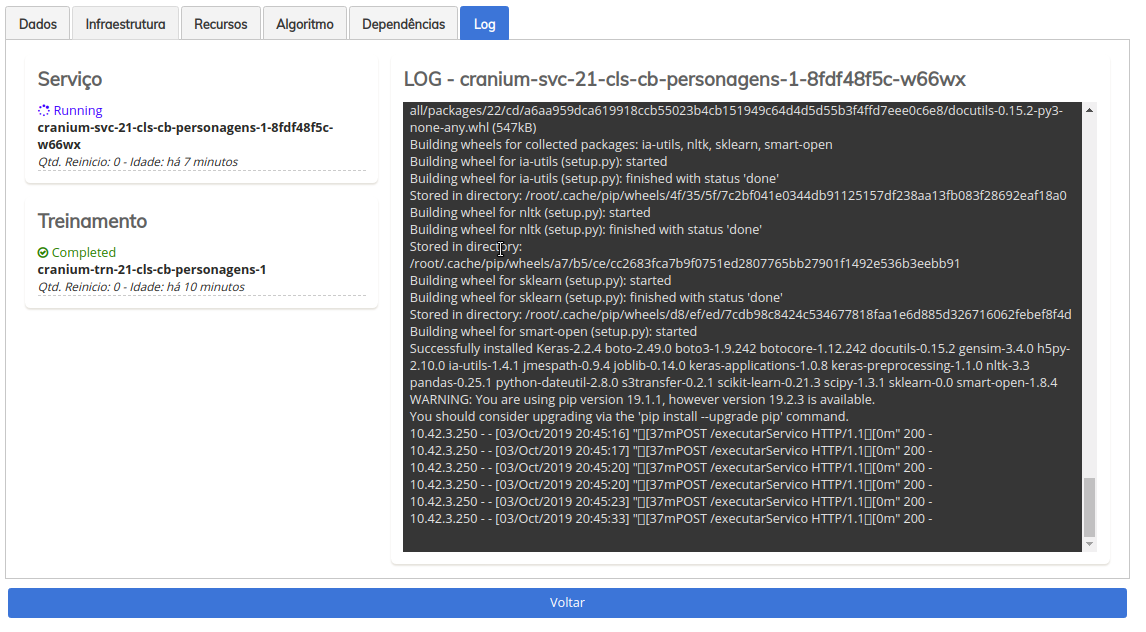
Finalizado o treinamento, agora o SINAPSES irá subir o pod de serviço, responsável por receber as requisições para predição, clique nele e você poderá ver resultados semelhantes a imagem acima.
-
Se formos até os logs da nossa versão, poderemos ver o pod
cranium-trnde treinamento sendo criado, até finalizar o processo de treinamento.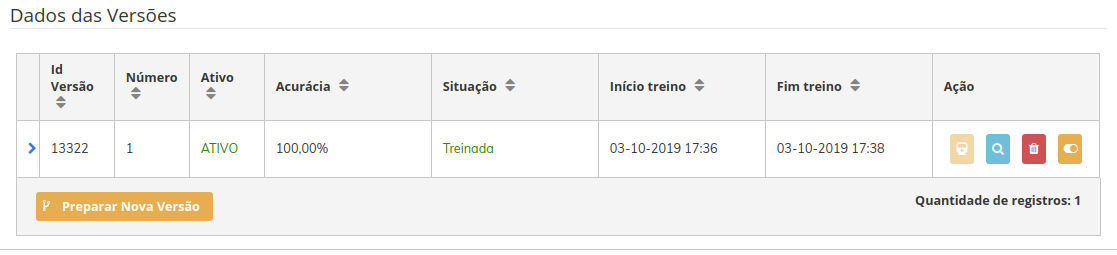
Finalizado o treinamento, agora o SINAPSES irá subir o pod (craniun-svc) de serviço, responsável por receber as requisições para predição, clique nele e você poderá ver resultados semelhantes a imagem acima.
Eclipse/Shell - Algoritmo
Você deverá repetir a mesma sequência já apresentada com o Jupyter Notebook, porém fazendo as devidas adequações a sua IDE.
Para download do algoritmo, clique no link abaixo:
Certifique-se que em sua IDE, o ambiente Pyenv criado está atividado, e caso utilize o shell, não esqueça de executar o comando abaixo antes de rodar o algorítmo.
pyenv activate cranium
Testando o Modelo
Para avaliar o funcionamento do seu modelo, há uma tela específica para esta finalidade na própria plataforma. Vá ao menu EDITOR > Específico.

-
Na tela que será apresentada, pesquise e selecione a versão do modelo criado.
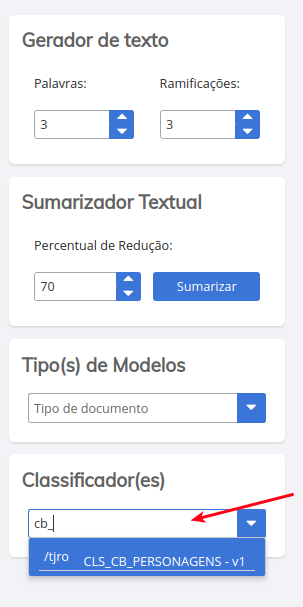
-
Uma vez que tenha selecionado o modelo, você pode testa-lo digitando o colando algum conteudo no editor. Conforme edita, o SINAPSES irá realizar predições sobre o conteúdo que está sendo ofertado. Em nosso caso, nosso modelo foi treinado para realizar predições sobre personagens da DC e MARVEL.
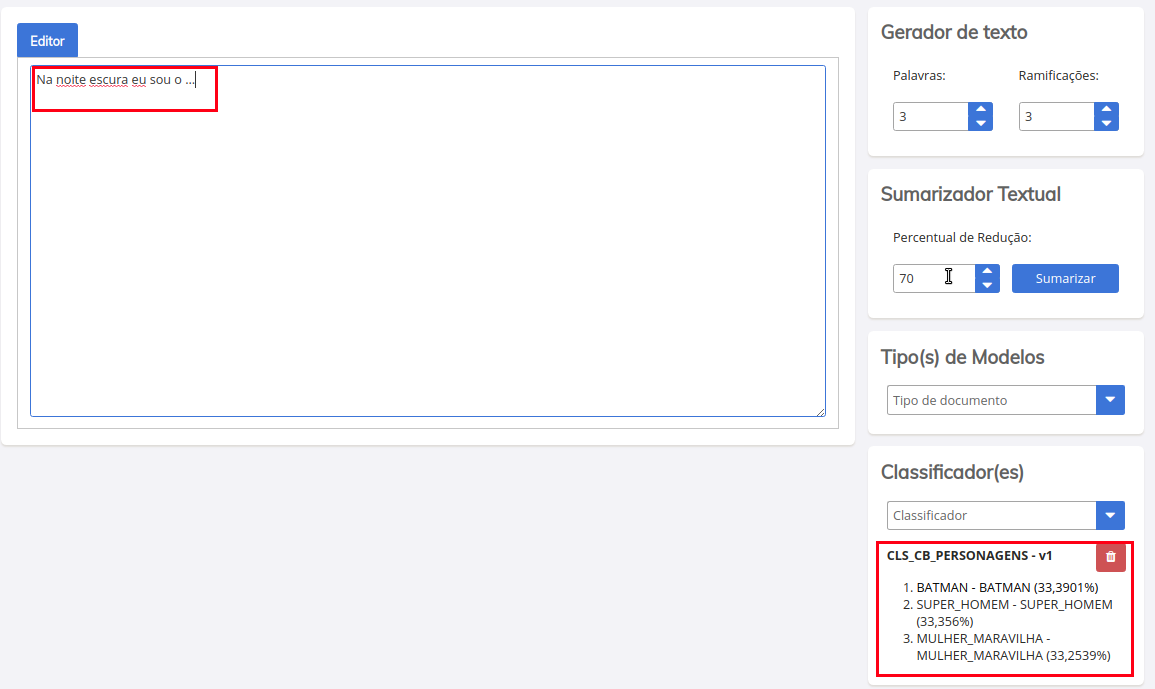
Na imagem acima, nosso modelo realizou uma predição com 3 saídas, em ordem de certeza (%). Embora tenham ficado bem próximas, a classe campeã foi BATMAN. Em um caso real, caberia ao operado humano do sistema escolher entre as três opções. E em caso de divergência, a API recebe um retorno informando que houve descordância, registrando na plataforma esta divergência para resolução futura e reaprendizado do modelo.
Consultando A API
Tomando com base a requisição realizada acima, temos os seguinte cenário:
URL: https://sinapses-backend-hml.ia.pje.jus.br/rest/modelo/executarServico/-tjro/CLS_CB_PERSONAGENS/1
Todos os modelos utilizaram a mesma raíz de requisição /rest/modelo/executarServico/, e terão suas peculiaridades conforme a descrição abaixo:
-
https://sinapses-backend-hml.ia.pje.jus.br - servidor
{servidor}. -
/rest/modelo/executarServico- serviço{servico}. -
/-tjro- dominio no qual o modelo está hospedado{dominio}. -
/CLS_CB_PERSONAGENS- nome do modelo{nome_modelo}. -
/1- número do modelos{versao_modelo}.
Endereço da API: {servidor}/{servico}/{dominio}/{nome_modelo}/{versao_modelo}
{
"mensagem": {
"tipo": "TEXTO",
"conteudo": "TmEgbm9pdGUgZXNjdXJhIGV1IHNvdSBv"
},
"quantidadeClasses": 3
}
{
"classeConvicto":{
"codigo":"BATMAN",
"descricao":"BATMAN"
},
"resultados":[
{
"classe":{
"codigo":"BATMAN",
"descricao":"BATMAN"
},
"conviccao":33.39008464003392
},
{
"classe":{
"codigo":"SUPER_HOMEM",
"descricao":"SUPER_HOMEM"
},
"conviccao":33.35604335701127
},
{
"classe":{
"codigo":"MULHER_MARAVILHA",
"descricao":"MULHER_MARAVILHA"
},
"conviccao":33.25387200295481
}
]
}
"Re-treinando" o modelo
No SINAPSES o retreino do modelo é diferente, pois não iremos de fato retreinar, mantendo a mesma API, iremos gerar um nova versão do modelo, com uma nova API. Isso ficará mais claro com os exemplos as seguir.
-
Mas antes de retreinar nosso modelo, é necessário um motivo. Nesse caso, o nosso cenário é: a primeira versão do nosso modelo foi treinada com poucos exemplos, agora temos novos exemplos, e queremos efetuar este retreino para verificar se haverá melhoria na eficiência do modelo. Voltemos então ao nosso classificador, conforme demonstrado anteriormente, e clique no menu IMPORTAR EXEMPLOS EM LOTE (2).
Faça todo processo de importação, mas agora utilize o arquivo do link abaixo.
Uma vez realizado este procedimento, se o dataset já estivesse com cada exemplo marcado como VALIDO, como ocorreu no primeiro dataset, íriamos direto para o próximo passo e gerar uma nova versão. Mas não é o caso, este nosso dataset não está validade, e necessita passar pela curadoria. Esse processo de curadoria, em casos reais, é realizado pela equipe de negócios. Os nossos novos exemplos foram importados em estã com status NÃO DEFINIDO.
-
Conforme explicado anteriomente, clique em RECLASSIFICADOR EXEMPLOS, pesquise pelo seu classificador.
-
Desmarque os botões VALIDO e INVALIDO, deixando apenas NÃO DEFINIDO, isso irá apresentar para reclassificação apenas os nossos novos exemplos. Verifique se o conteúdo de cada documento condiz com a classe/rótulo e clique em VALIDAR(botão verde) até que todos os documentos disponíveis sejam validados e não reste mais exemplos em tela.
-
Com os documentos classificados, Voltemos então ao nosso classificador, conforme a FIGURA 22, e clique no menu PREPARAR UMA NOVA VERSÃO(4).
A tela abaixo será apresentada:
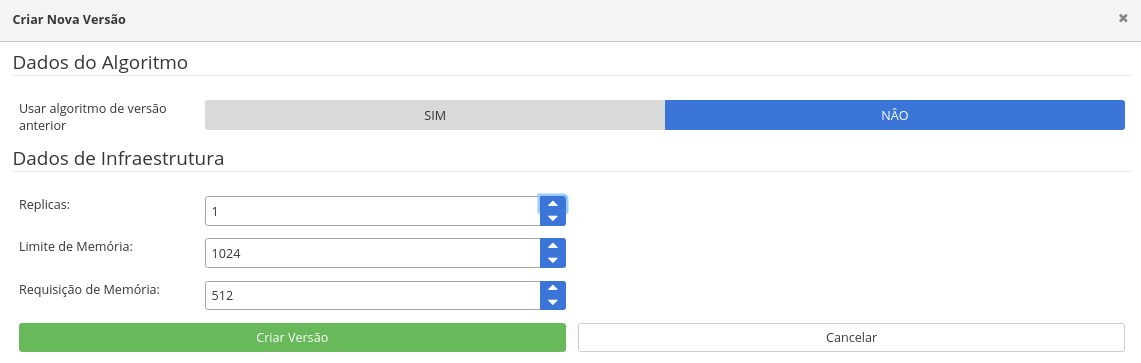
Algumas considerações precisam ser feitas antes de avançarmos ao próximo passo. Nesse ponto, se clicarmos em CRIAR VERSÃO, estaríamos repetindo todo o nosso pipeline já apresentado anteriormente para treinamento do nosso modelo. Mas não é o que queremos, pois isso nos levaria a ter que novamente gerar um algorítmo para este modelo, e nosso modelo irá usar o mesmo algorítmo da versão anterior. Então, o SINAPSES nos oferece a possibilidade de retreino fazendo uso do algorítmo de versões antiores.
-
Na tela apresentada anteriormente, clique em SIM (Usar algorítmo de versão anterior), e a tela abaixo será apresentada.
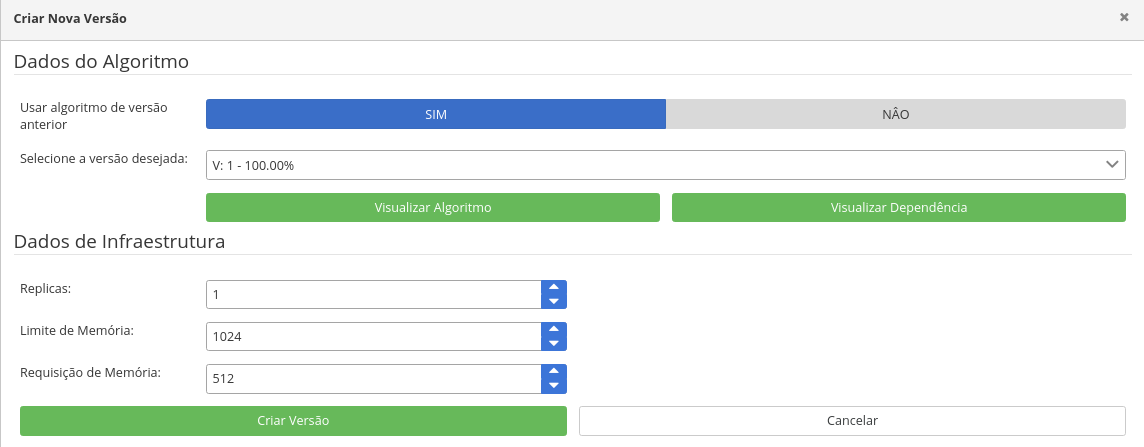
-
Diferentemente do processo anterior, a plataforma agora se encarregará dos próximos passos, e irá gerar uma nova versão do modelo, o qual ficará PEDENTE DE TREINAMENTO, e uma vez treinado, disponibilizará uma nova API para consumo (INATIVA). Por padrão, se a acurácia da nova versão for igual o inferior a versão anterior, a plataforma deixar a mesma inativa, cabendo a você julgar a necessidade de manter mais de uma versão ativa.
-
Aguarde o treinamento, e após finalizado, verifique em DADOS DAS VERSÕES (do modelo). Nesta tela você poderá ativar e desativar as versões do seu modelo.
Agora é com você!
Nesta seção, você irá gerar produtos para o seu tribunal. Iremos compartilhar aqui, todos os algoritmos e processos para geração dos modelos disponíveis no ambiente do SINAPSES, com o passo a passo mínimo, somado ao seu conhecimento em programação, você poderá replicar versões em acordo com a realidade do seu tribunal.
Cookbook - Datasets
Na sessões abaixo, serão apresentadas formas de extrair datasets que servirão para gerar novos modelos para os algorítmos de IA disponíveis, fazendo uso da base do sistema processual do seu tribunal.
Movimento inteligente
Faça o download do kit de extração de acordo com o seus sistema processual.
| Nome | Descrição | Sistema processual | Versão | Requisitos | Fonte |
|---|---|---|---|---|---|
| Movimento Inteligente | Este kit contem os scripts necesários para que você efetue o download dos documentos do PJE necessários a geração do dataset para o modelo. | PJe | 1.0.1 | Sistema Operacional Linux | Download |
Verifique o seu ambiente
Certifique-se de que o docker e docker compose estejam instalados em sua máquina, caso não esteja, acesse a documentação oficial e realize a instalação de acordo com a versão do seu sistema operacional.
Execute o script
Após ter descompactado o arquivo do kit, abra um terminal shell do Linux, e execute o script conforme abaixo:
chmod +x script-extracao.sh
./script-extracao.sh
Aguardando a finalização
Uma pasta no mesmo local em que o arquivo foi executada será criada, onde serão armazenados os documentos extraídos. Você poderá acompanhar a finalização do processo através dos logs do docker, para o container criado.
docker logs -f nomedocontainer
Importando e criando o modelo
Terminado o processamento, realize os passos descritos para criação de um modelo (classificador), prepare o dataset e solicite o algoritmo para ajuste e execução.
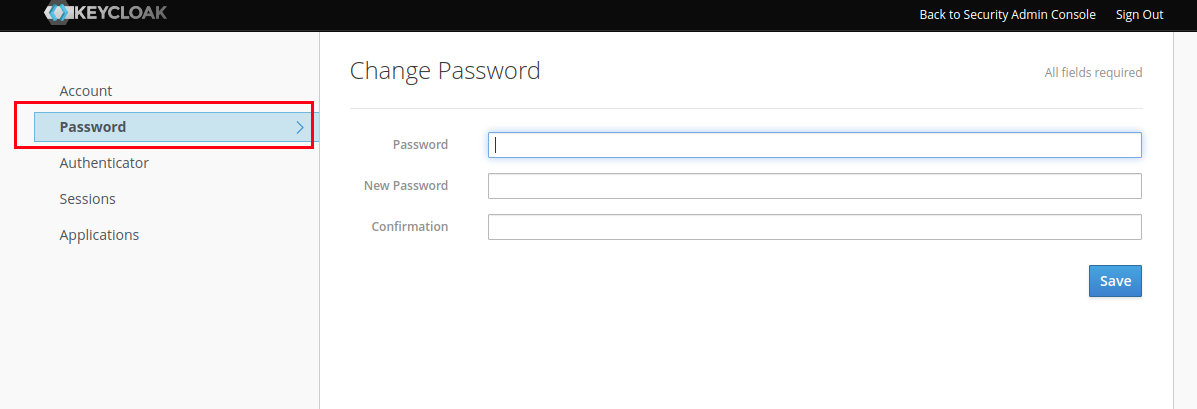
Alterar Senha
-
Acesse a url http://keycloak.ia.cnj.jus.br/auth, clique em ADMIN CONSOLE conforme a imagem abaixo para ter acesso ao painel de controle do Keycloack, e faça logon com suas credenciais.
-
Na tela que será renderizada, no canto superior direito, clique em MANAGE ACCOUNT.

-
Clique em PASSWORD, digite a senha antiga, a nova senha, confirme a nova senha e clique em SAVE.